0 天,部分内容可能已经过时,请注意甄别。
什么是protobuf 一拿到网站,F12查看是否有相关数据的请求接口
application/json: JSON数据格式
application/octet-stream : 二进制流数据
application/x-www-form-urlencoded : 中默认的encType,form表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式)
multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式
通过查询知道这是protobufhttps://blog.csdn.net/dideng7039/article/details/101869819
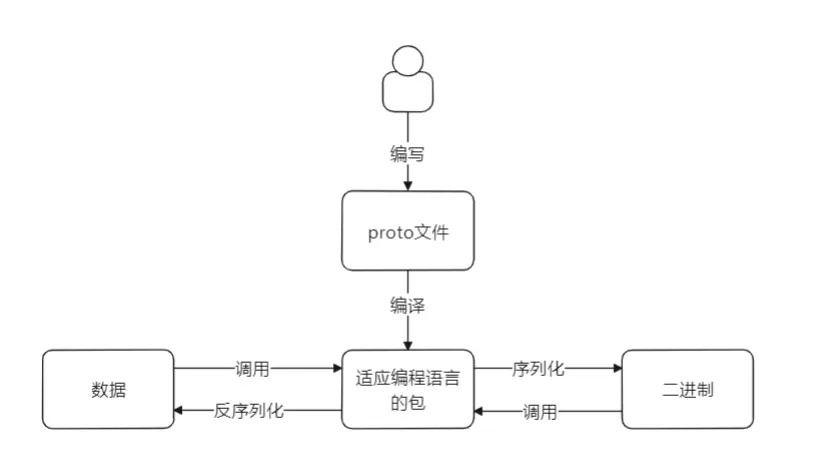
那如何使用protobuf? 开发者需要先编写proto文件,在proto文件中编写预期的数据类型、数据字段、默认值等
这里先写一个简单proto,在编译成js版本,看看里面大概的结构长什么样https://github.com/protocolbuffers/protobuf/releases/
英文 中文 备注
enum
枚举(数字从零开始) 作用是为字段指定某”预定义值序列”
enum Type {DEFAULT = 0;success = 1; fail= -1;}
message
消息体
message Student{}
repeated
数组/集合
repeated Student student = 1
import
导入定义
import “protos/other_protos.proto”
//
注释
//用于注释
extend
扩展
extend Student {}
package
包名
相当于命名空间,用来防止不同消息类型的明明冲突
现在写一个简单的proto文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 syntax = "proto3" ; enum Gender { boy=0 ; girl=1 ; } enum Score { DEFAULT = 0 ; success = 1 ; fail = -1 ; } message Student { string name = 1 ; int32 age = 2 ; Gender gender = 3 ; message Subject { string name = 1 ; Score score = 2 ; } repeated Subject subject = 4 ; }
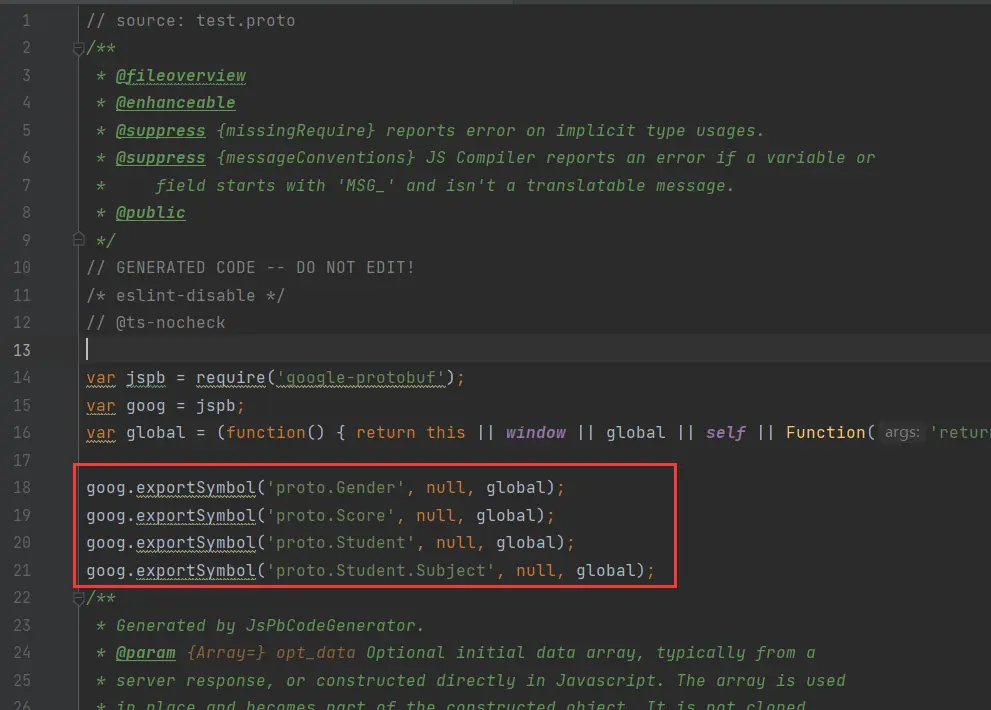
编译为JS包
1 2 protoc --js_out=. .\test.proto3 protoc --js_out=import_style=commonjs,binary:. test.proto
两条语句都可以,第一条会拆分成多个文件,第二条是合并成一个,推荐使用第二条
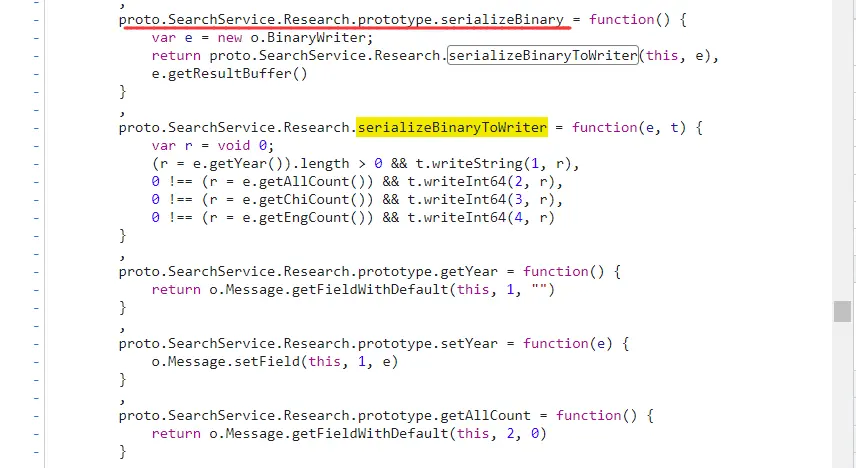
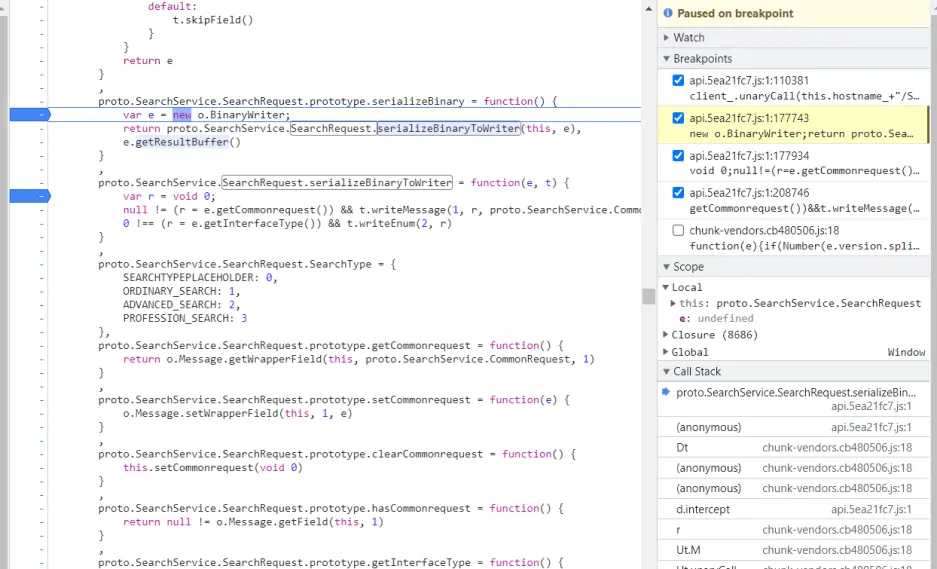
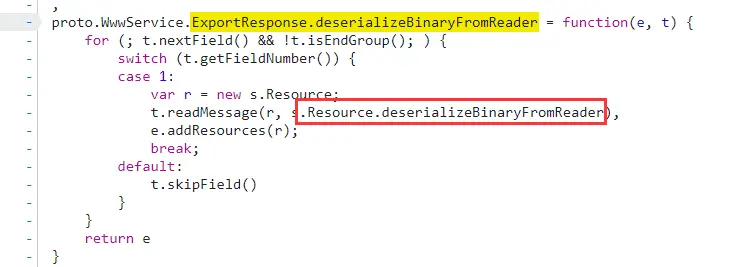
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 proto.Student .serializeBinaryToWriter = function (message, writer ) { var f = undefined ; f = message.getName (); if (f.length > 0 ) { writer.writeString ( 1 , f ); } f = message.getAge (); if (f !== 0 ) { writer.writeInt32 ( 2 , f ); } f = message.getGender (); if (f !== 0.0 ) { writer.writeEnum ( 3 , f ); } f = message.getSubjectList (); if (f.length > 0 ) { writer.writeRepeatedMessage ( 4 , f, proto.Student .Subject .serializeBinaryToWriter ); } };
这一段序列化的代码中出现了如下的方法名:
getName, writeString
这一整个判断,这意味 Student中定义了四个数据变量, 序号为1, 2,3,4,而数据类型和变量名可以根据其调用的方法推出
序号为1的数据类型为String,变量名为name
字符串和整数型一看就明了,不做过多解释,下面了解Message 和Enum Message是什么数据类型?
1 proto.Student.Subject.serializeBinaryToWriter
再来看看Student的
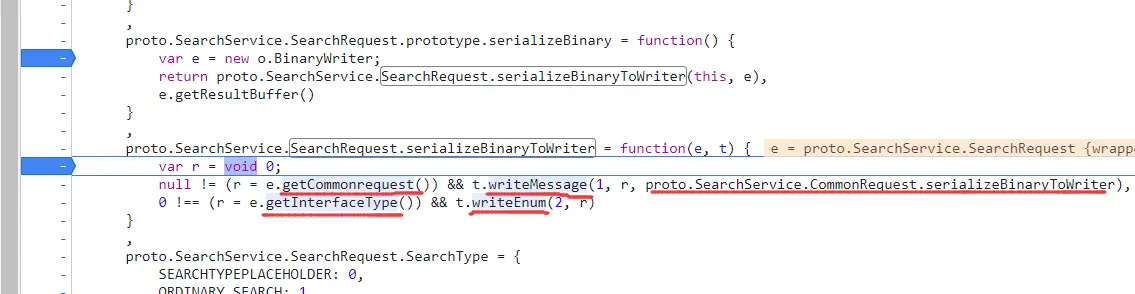
1 proto.Student.serializeBinaryToWriter
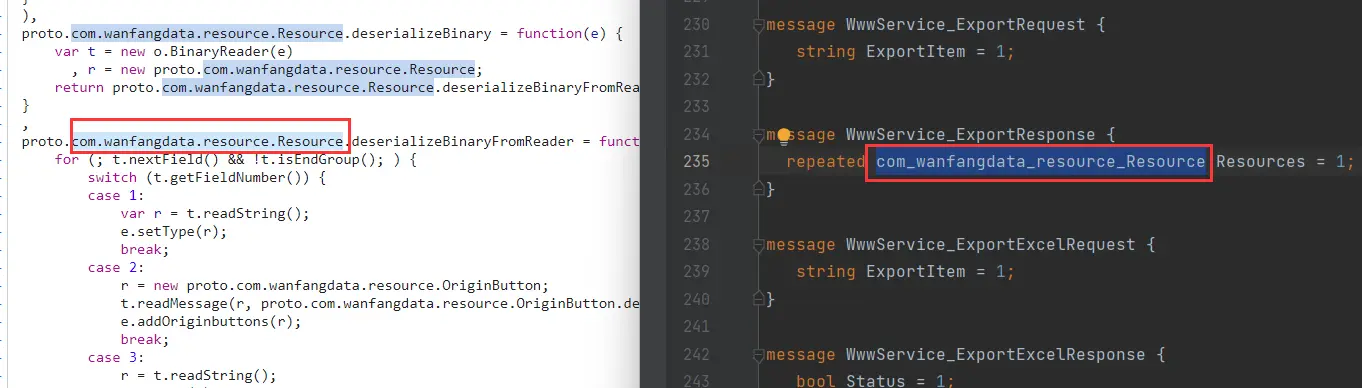
到这里可知,Subject定义在Student里面且类型是MessageMessage 类型的Subject被repeated 修饰,即Subject是一个包含多个Subject实例的数组Enum是什么数据类型? 必须要有为0的默认选项 writeEnum 就知道这个数据为Enum类型 repeated 也可以修饰Enum ,其对应的JS写操作的方法为writePackedEnum 则好似的多选框,至少选择一个,可选择多个 小结一下: 被repeated修饰的message类型的数据,看作是一个包含任意个某message类型数据的数组 被repeated修饰的enum类型的数据,看作是一个包含任意个整数类型数据的整型数组
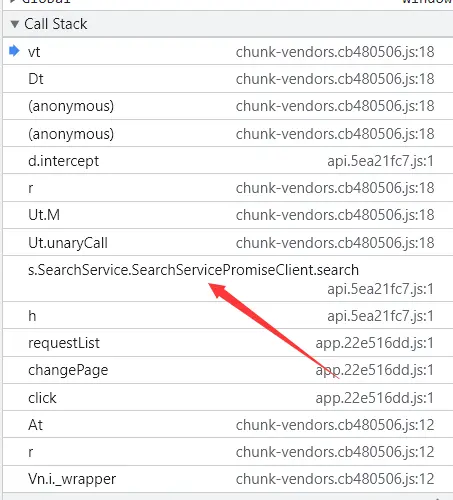
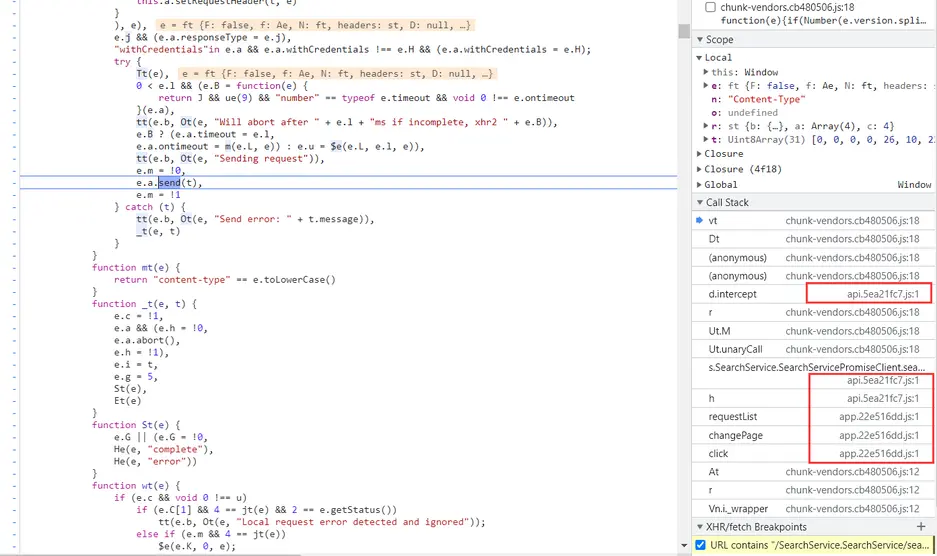
调试JS反写proto 目标网站:aHR0cHM6Ly9zLndhbmZhbmdkYXRhLmNvbS5jbi9wYXBlcj9xPXB5dGhvbg==
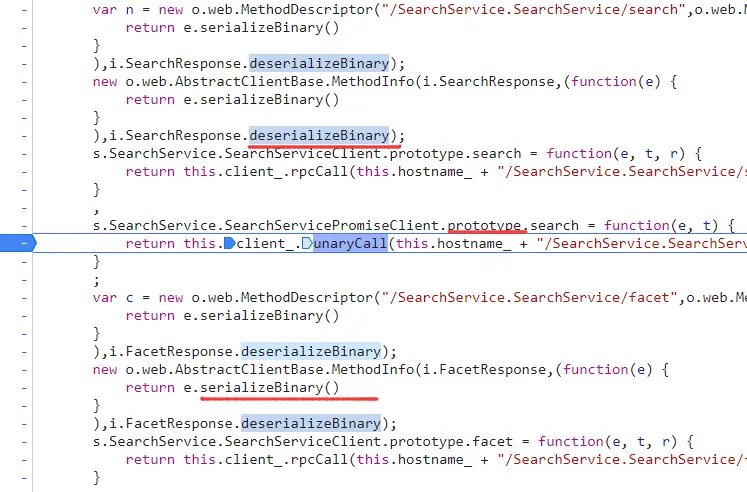
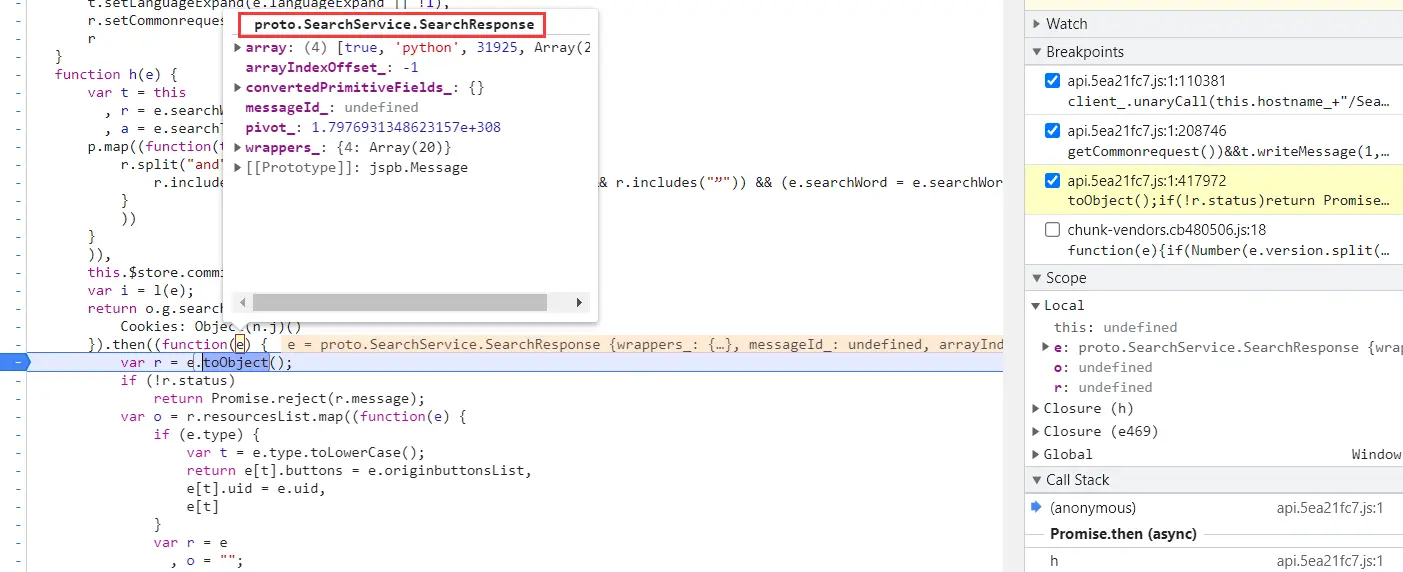
toObject 将获取到的数据转成结构化数据 deserializeBinary 二进制数据转换成数组结构(反序列化 | 获取到的数据需要Uint8Array转成二进制) deserializeBinaryFromReader 根据规则,将二进制数据转换成数组结构 serializeBinary 将数据转成二进制(序列化) serializeBinaryToWriter 根据规则,将数据转换成二进制数据(序列化)
1 2 3 4 message SearchService { message SearchRequest { } }
继续调试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 syntax = "proto3" ; message SearchService { message SearchRequest { CommonRequest commonRequest = 1 ; InterfaceType interfaceType = 2 ; } message CommonRequest { } enum InterfaceType { DEFAULT = 0 ; } }
关于变量名是什么,这个其实不重要
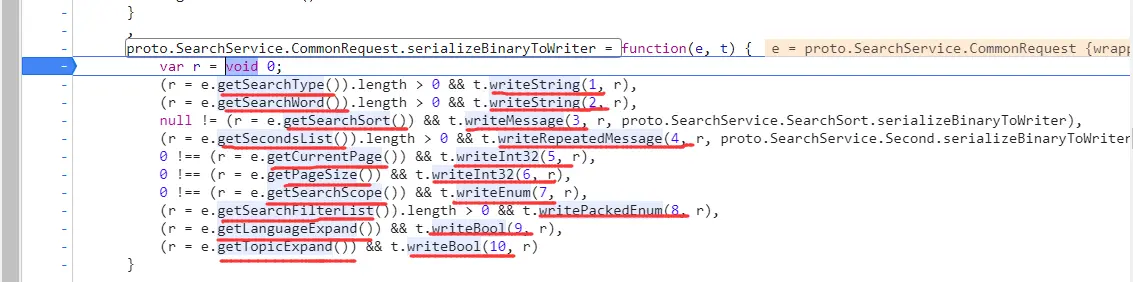
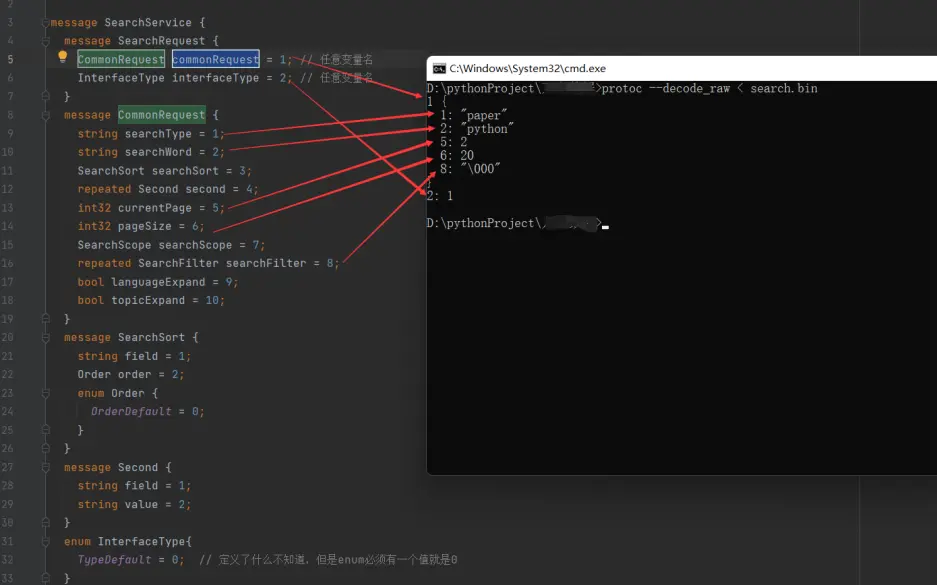
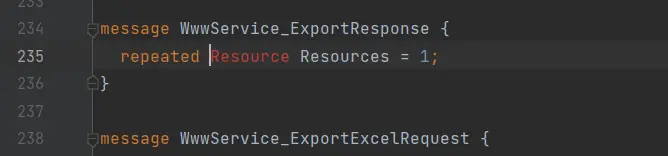
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 message SearchRequest { CommonRequest commonRequest = 1 ; InterfaceType interfaceType = 2 ; } message CommonRequest { string searchType = 1 ; string searchWord = 2 ; SearchSort searchSort = 3 ; repeated Second second = 4 ; int32 currentPage = 5 ; int32 pageSize = 6 ; SearchScope searchScope = 7 ; repeated SearchFilter searchFilter = 8 ; bool languageExpand = 9 ; bool topicExpand = 10 ; } message SearchSort { } message Second { } enum InterfaceType { TypeDefault = 0 ; } enum SearchScope { ScopeDefault = 0 ; } enum SearchFilter { FilterDefault = 0 ; } }
SearchSort和Second都是在SearchService定义的,Ctrl + F搜索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 syntax = "proto3" ; message SearchService { message SearchRequest { CommonRequest commonRequest = 1 ; InterfaceType interfaceType = 2 ; } message CommonRequest { string searchType = 1 ; string searchWord = 2 ; SearchSort searchSort = 3 ; repeated Second second = 4 ; int32 currentPage = 5 ; int32 pageSize = 6 ; SearchScope searchScope = 7 ; repeated SearchFilter searchFilter = 8 ; bool languageExpand = 9 ; bool topicExpand = 10 ; } message SearchSort { string field = 1 ; Order order = 2 ; enum Order { OrderDefault = 0 ; } } message Second { string field = 1 ; string value = 2 ; } enum InterfaceType { TypeDefault = 0 ; } enum SearchScope { ScopeDefault = 0 ; } enum SearchFilter { FilterDefault = 0 ; } }
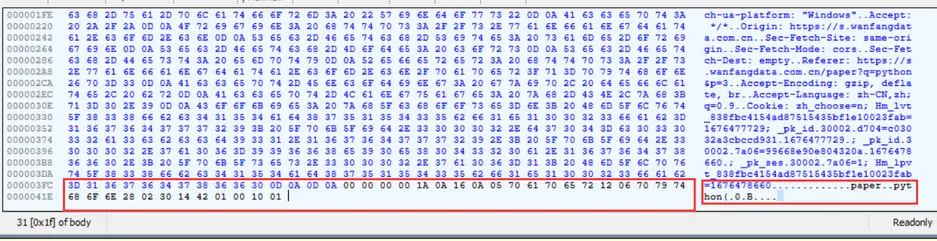
对于所有的enum枚举类,至少填充一个默认值0,且变量名唯一 字节数据是可以通过protoc编译器解码出来的
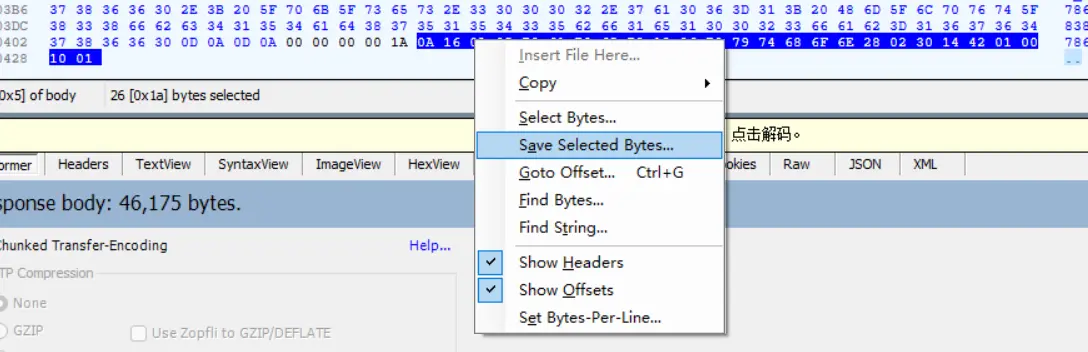
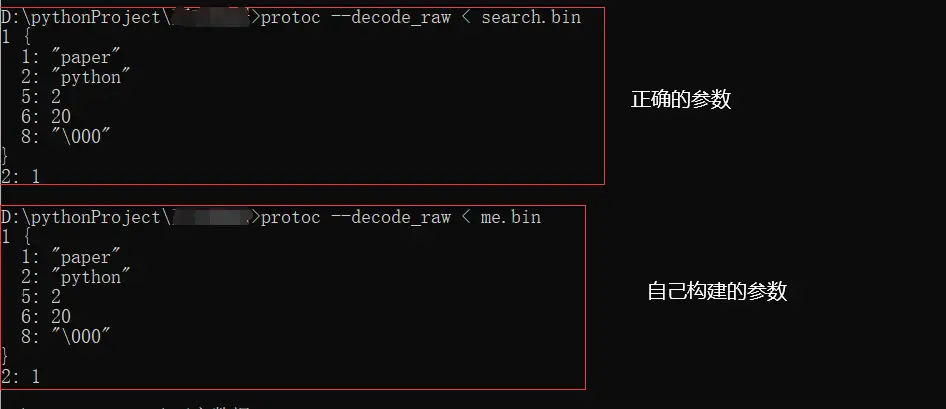
1 2 3 4 5 6 7 8 9 >protoc --decode_raw < get_req.bin 1 { 1: "paper" 2: "python" 5: 2 6: 20 8: "\000" } 2: 1
与上面编写好的proto文件进行对比
实现请求 编译proto为python包,构建参数,序列化参数,发送请求
1 protoc --python_out=. ./search.proto
目录下生成了search_pb2.py 拖入项目中,需要使用时就调用即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import search_pb2 as pb search_request = pb.SearchService.SearchRequest() search_request.commonRequest.searchType = 'paper' search_request.commonRequest.searchWord = 'python' search_request.commonRequest.currentPage = 2 search_request.commonRequest.pageSize = 20 search_request.commonRequest.searchFilter.append(0 ) search_request.interfaceType = 1 form_data = search_request.SerializeToString() print (form_data)with open ('me.bin' , mode="wb" ) as f: f.write(form_data) print (search_request.SerializeToString().decode())
至此,请求参数的序列化已经是完成了
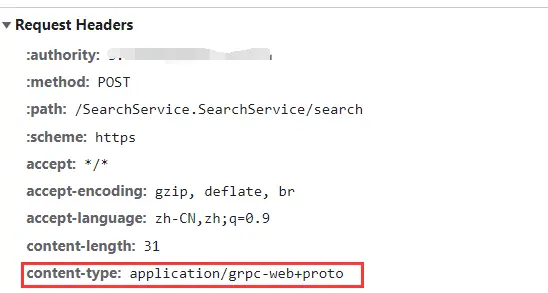
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import search_pb2 as pb import requestssearch_request = pb.SearchService.SearchRequest() search_request.commonRequest.searchType = 'paper' search_request.commonRequest.searchWord = 'python' search_request.commonRequest.currentPage = 2 search_request.commonRequest.pageSize = 20 search_request.commonRequest.searchFilter.append(0 ) search_request.interfaceType = 1 form_data = search_request.SerializeToString() print (form_data)bytes_head = bytes ([0 , 0 , 0 , 0 , len (form_data)]) print (bytes_head+form_data)headers = { "Accept" : "*/*" , "Accept-Language" : "zh-CN,zh;q=0.9,zh-TW;q=0.8" , "Content-Type" : "application/grpc-web+proto" , "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36" , } url = "https://*********/SearchService.SearchService/search" response=requests.post(url,headers=headers,data=bytes_head+form_data) print (response.content)
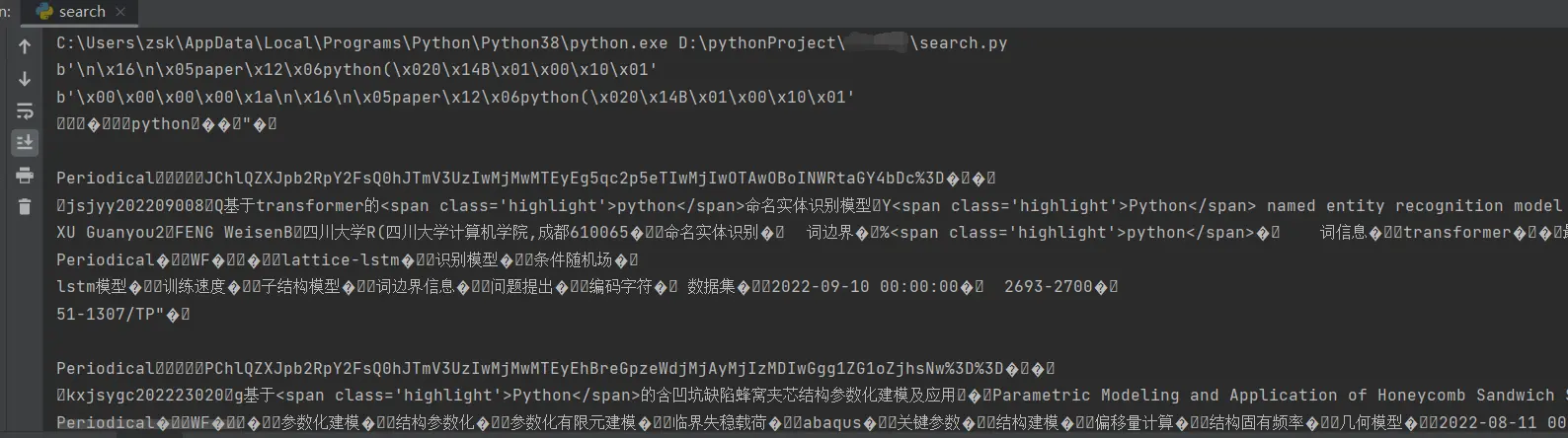
响应处理 我们构造了请求的proto文件,并成功用python发包获得了数据,但是得到的数据和f12得到的数据是一样的乱码如下图
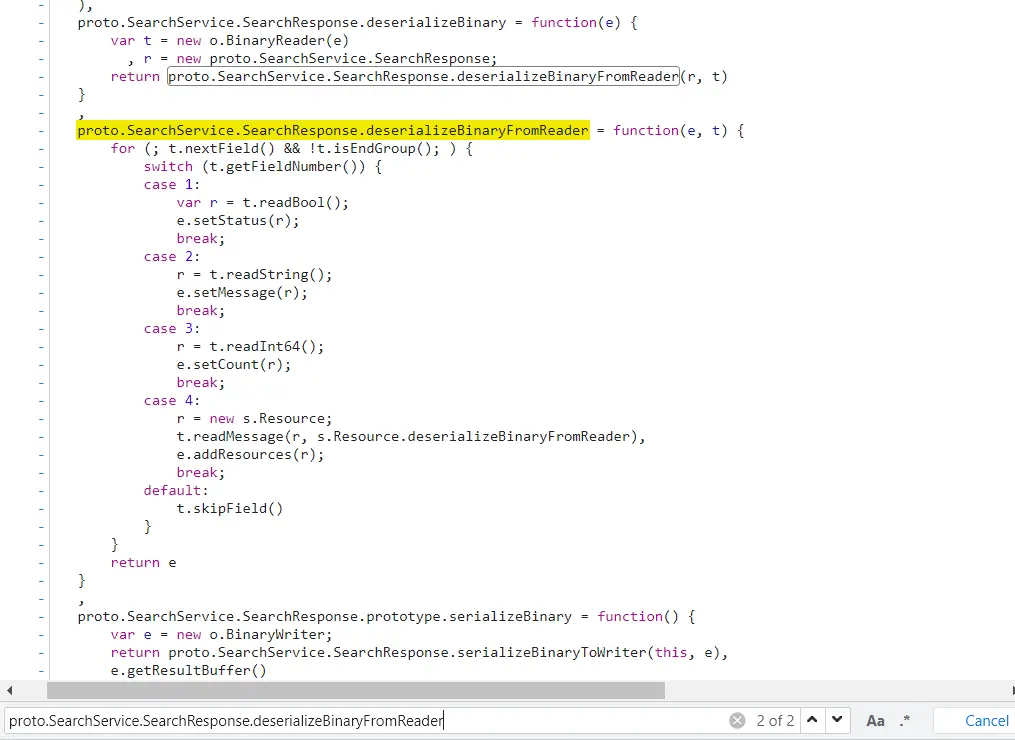
方法一 写对应的响应的proto文件,和发包一样。当然可以和发包写在一起。 deserializeBinary——deserializeBinaryFromReader ( 重点核心
1 npm install @babel/core --save-dev
执行ast代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 const parser = require ("@babel/parser" );const template = require ("@babel/template" ).default ;const traverse = require ("@babel/traverse" ).default ;const t = require ("@babel/types" );const generator = require ("@babel/generator" );const fs = require ("fs" );function wtofile (path, flags, code ) { var fd = fs.openSync (path,flags); fs.writeSync (fd, code); fs.closeSync (fd); } function dtofile (path ) { fs.unlinkSync (path); } var file_path = 'test.js' ; var jscode = fs.readFileSync (file_path, { encoding : "utf-8" }); let ast = parser.parse (jscode);let proto_text = `syntax = "proto3"; // protoc --python_out=. app_proto2.proto ` ;traverse (ast, { MemberExpression (path){ if (path.node .property .type === 'Identifier' && path.node .property .name === 'deserializeBinaryFromReader' && path.parentPath .type === 'AssignmentExpression' ){ let id_name = path.toString ().split ('.' ).slice (1 , -1 ).join ('_' ); path.parentPath .traverse ({ VariableDeclaration (path_2){ if (path_2.node .declarations .length === 1 ){ path_2.replaceWith (t.expressionStatement ( t.assignmentExpression ( "=" , path_2.node .declarations [0 ].id , path_2.node .declarations [0 ].init ) )) } }, SwitchStatement (path_2){ for (let i = 0 ; i < path_2.node .cases .length - 1 ; i++) { let item = path_2.node .cases [i]; let item2 = path_2.node .cases [i + 1 ]; if (item.consequent .length === 0 && item2.consequent [1 ].expression .type === 'SequenceExpression' ){ item.consequent = [ item2.consequent [0 ], t.expressionStatement ( item2.consequent [1 ].expression .expressions [0 ] ), item2.consequent [2 ] ]; item2.consequent [1 ] = t.expressionStatement ( item2.consequent [1 ].expression .expressions [1 ] ) }else if (item.consequent .length === 0 ){ item.consequent = item2.consequent }else if (item.consequent [1 ].expression .type === 'SequenceExpression' ){ item.consequent [1 ] = t.expressionStatement ( item.consequent [1 ].expression .expressions [1 ] ) } } } }); let id_text = 'message ' + id_name + ' { ' ; let let_id_list = []; try { for (let i = 0 ; i < path.parentPath .node .right .body .body [0 ].body .body [0 ].cases .length ; i++) { let item = path.parentPath .node .right .body .body [0 ].body .body [0 ].cases [i]; if (item.test ){ let id_number = item.test .value ; let key = item.consequent [1 ].expression .callee .property .name ; let id_st, id_type; if (key.startsWith ("set" )){ id_st = "" ; }else if (key.startsWith ("add" )){ id_st = "repeated" ; }else { continue } key = key.substring (3 , key.length ); id_type = item.consequent [0 ]; if (id_type.expression .right .type === 'NewExpression' ){ id_type = generator.default (id_type.expression .right .callee ).code .split ('.' ).slice (1 ).join ('_' ); }else { switch (id_type.expression .right .callee .property .name ) { case "readString" : id_type = "string" ; break ; case "readDouble" : id_type = "double" ; break ; case "readInt32" : id_type = "int32" ; break ; case "readInt64" : id_type = "int64" ; break ; case "readFloat" : id_type = "float" ; break ; case "readBool" : id_type = "bool" ; break ; case "readPackedInt32" : id_st = "repeated" ; id_type = "int32" ; break ; case "readBytes" : id_type = "bytes" ; break ; case "readEnum" : id_type = "readEnum" ; break ; case "readPackedEnum" : id_st = "repeated" ; id_type = "readEnum" ; break ; } } if (id_type === 'readEnum' ){ id_type = id_name + '_' + key + 'Enum' ; if (let_id_list.indexOf (id_number) === -1 ){ id_text += '\tenum ' + id_type + ' { ' ; for (let j = 0 ; j < 3 ; j++) { id_text += '\t\t' + id_type + 'TYPE_' + j + ' = ' + j + '; ' ; } id_text += '\t} ' ; id_text += '\t' + id_st + ' ' + id_type + ' ' + key + ' = ' + id_number + '; ' ; let_id_list.push (id_number) } }else { if (let_id_list.indexOf (id_number) === -1 ){ id_text += '\t' + id_st + ' ' + id_type + ' ' + key + ' = ' + id_number + '; ' ; let_id_list.push (id_number) } } } } }catch (e){ } id_text += '} ' ; proto_text += id_text } } }); wtofile ('app_proto3.proto' , 'w' , proto_text);
这个ast代码单纯只是针对这个站点,其他站点也是类似分析。
1 protoc --python_out=. ./app_proto3.proto
然后发个请求试一试
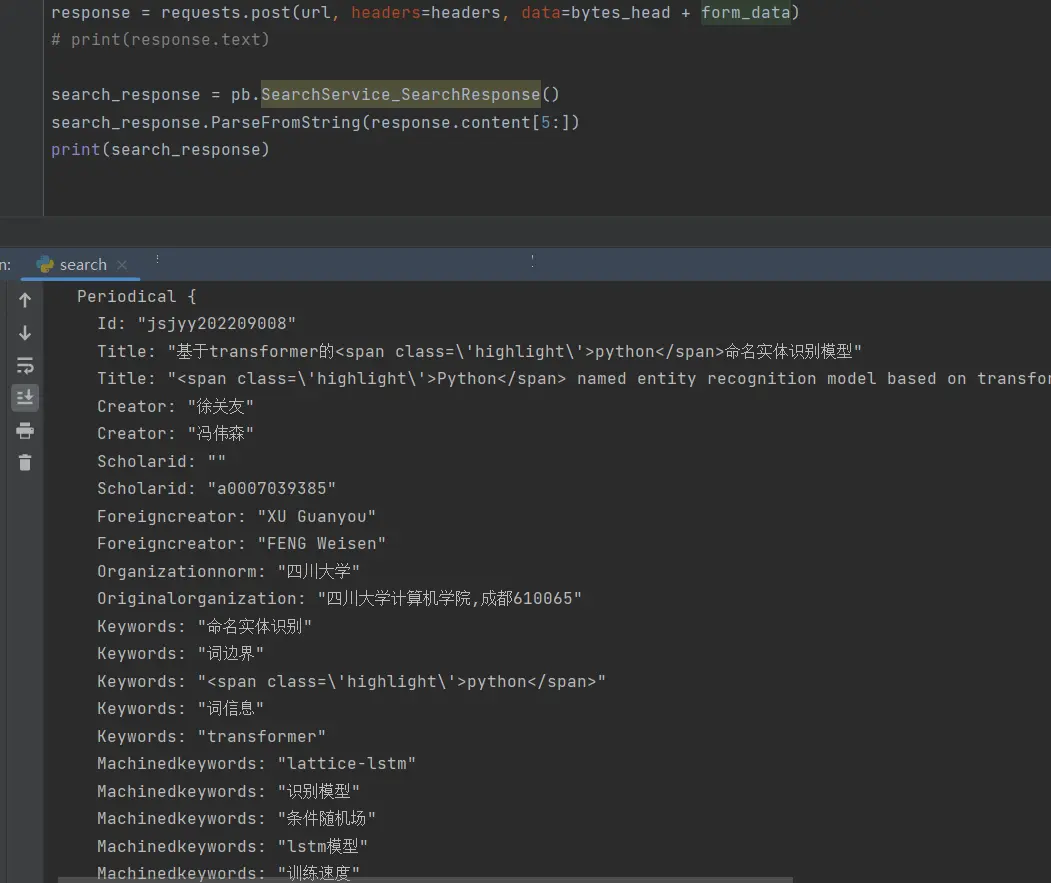
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import app_proto3_pb2 as pbimport requestssearch_request = pb.SearchService_SearchRequest() search_request.Commonrequest.SearchType = 'paper' search_request.Commonrequest.SearchWord = 'python' search_request.Commonrequest.CurrentPage = 2 search_request.Commonrequest.PageSize = 20 search_request.Commonrequest.SearchFilterList.append(0 ) search_request.InterfaceType = 1 form_data = search_request.SerializeToString() print (form_data)bytes_head = bytes ([0 , 0 , 0 , 0 , len (form_data)]) print (bytes_head + form_data)headers = { "Accept" : "*/*" , "Accept-Language" : "zh-CN,zh;q=0.9" , "Content-Type" : "application/grpc-web+proto" , "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36" , } url = "https://*********.com.cn/SearchService.SearchService/search" response = requests.post(url, headers=headers, data=bytes_head + form_data) search_response = pb.SearchService_SearchResponse() search_response.ParseFromString(response.content[5 :]) print (search_response)
可以看到很直观,取值也方便。serializeBinary——serializeBinaryFromReader ( 重点核心deserializeBinary——deserializeBinaryFromReader ( 重点核心
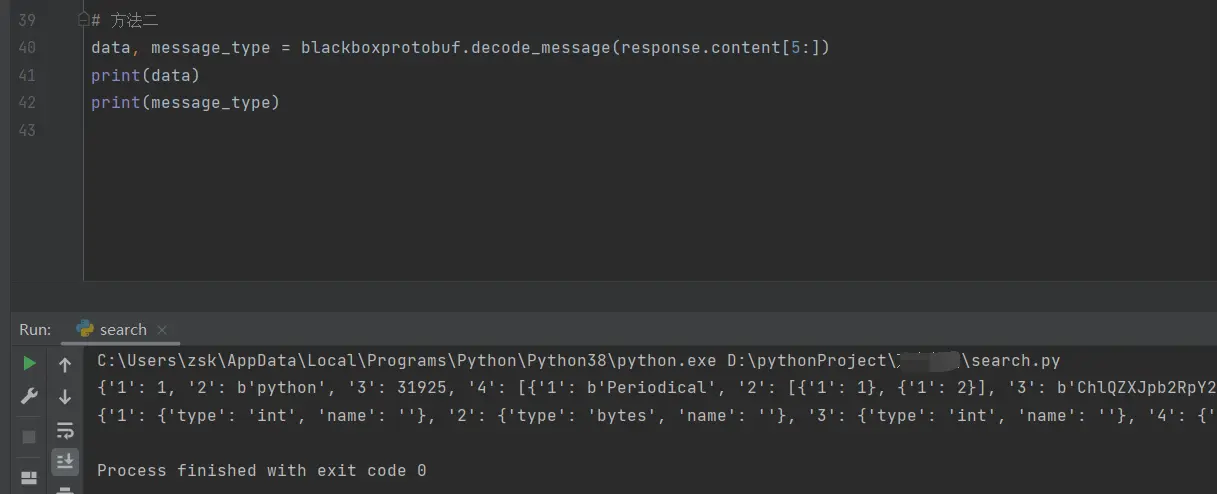
方法二 使用python应对protobuf的第三方库:blackboxprotobufByte类型数据 ),进行解protobuf格式数据
相关资料参考 https://blog.csdn.net/dideng7039/article/details/101869819 https://blog.csdn.net/qq_35491275/article/details/111721639 https://mp.weixin.qq.com/s/DzCz66_Szc7vfG6bpl956w https://blog.csdn.net/qq_56881388/article/details/128612717