
MD5算法实现:
输入:不定长度信息(要加密的信息)
输出:固定长度128-bits。由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值。
基本方式为:求余、取余、调整长度、与链接变量进行循环运算。得出结果。
填充
在MD5算法中,首先需要对输入信息进行填充,使其位长对512求余的结果等于448,并且填充必须进行,即使其位长对512求余的结果等于448。因此,信息的位长(Bits Length)将被扩展至N*512+448,N为一个非负整数,N可以是零。
填充的方法如下:
- 在信息的后面填充一个1和无数个0,直到满足上面的条件时才停止用0对信息的填充。
- 在这个结果后面附加一个以64位二进制表示的填充前信息长度(明文的长度,单位为Bit),如果二进制表示的填充前信息长度超过64位,则取低64位
经过这两步的处理,信息的位长=N512+448+64=(N+1)512,即长度恰好是512的整数倍。这样做的原因是为满足后面处理中对信息长度的要求。
初始化变量(变量值一般不变)
初始的128位值为初试链接变量,这些参数用于第一轮的运算,以大端字节序来表示,他们分别为:
A=0x01234567,
B=0x89ABCDEF,
C=0xFEDCBA98,
D=0x76543210。
(每一个变量给出的数值是高字节存于内存低地址,低字节存于内存高地址,即大端字节序。在程序中变量A、B、C、D的值分别为0x67452301,0xEFCDAB89,0x98BADCFE,0x10325476)
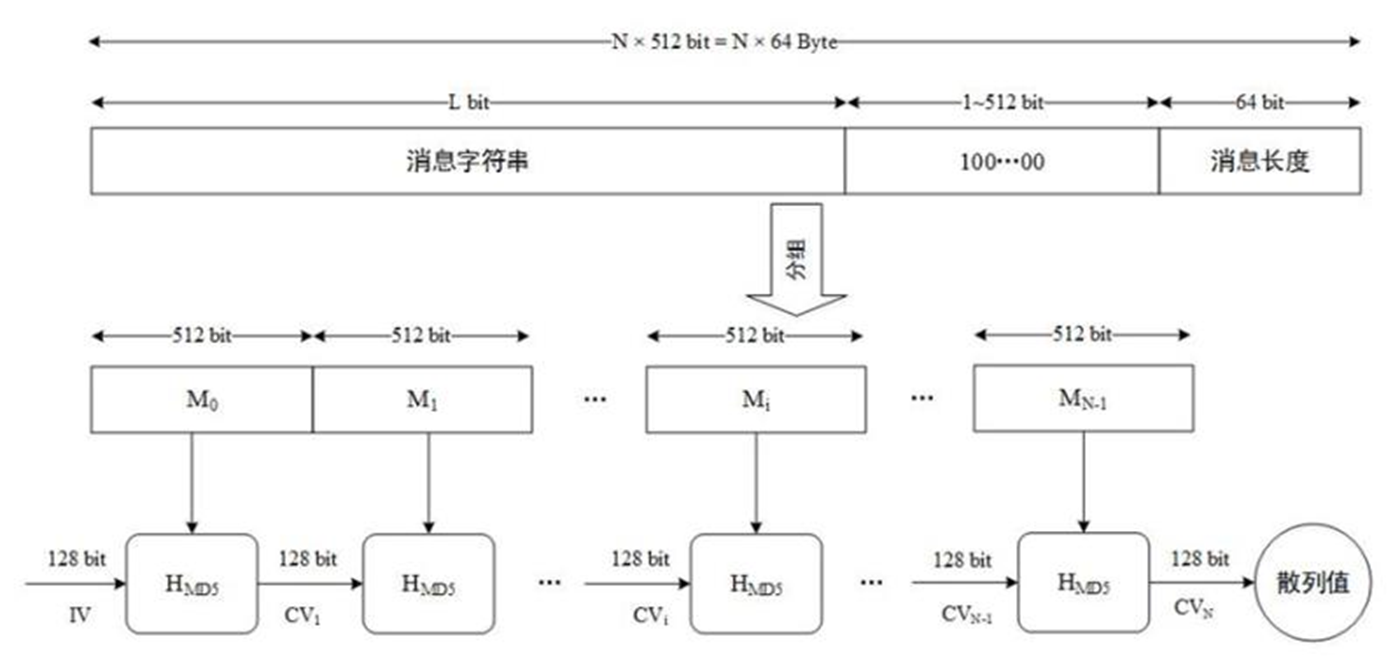
处理分组数据
消息分以512位为一分组进行处理,每一个分组进行上述4轮共64次计算后,将A,B,C,D分别加上计算得到的a,b,c,d。当做新的A,B,C,D,并将这4个变量赋值给a,b,c,d再进行下一分组的运算。由于填充后的消息长度为(N+1)*512,则共需计算N+1个分组。计算所有数据分组后,这4个变量为最后的结果,即MD5值。
每一分组的算法流程如下:
(1)第一分组需要将上面四个链接变量复制到另外四个变量中:A到a,B到b,C到c,D到d。
(2)从第二分组开始的变量为上一分组的运算结果,即A = a, B = b, C = c, D = d。
主循环有四轮(MD4只有三轮),每轮循环都很相似。第一轮进行16次操作。每次操作对a、b、c和d中的其中三个作一次非线性函数运算,然后将所得结果加上第四个变量,文本的一个子分组和一个常数。再将所得结果向左环移一个不定的数,并加上a、b、c或d中之一。最后用该结果取代a、b、c或d中之一。
一个MD5运算由类似的64次循环构成,分成4组16次。
F :一个非线性函数,一个函数运算一次
Mi :表示一个 32-bits 的输入数据
Ki:表示一个 32-bits 常数,用来完成每次不同的计算。
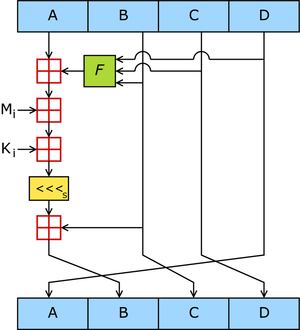
说明:
( (a + 线性函数(b,c,d) + Mj + Ki) << s) + a == B
以下是每次操作中用到的四个非线性函数(每轮一个)。
F( X ,Y ,Z ) = ( X & Y ) | ( (~X) & Z ) ==> If X then Y else Z
G( X ,Y ,Z ) = ( X & Z ) | ( Y & (~Z) ) ==> If Z then X else Y
H( X ,Y ,Z ) =X ^ Y ^ Z ==> If X=Y then Z else ~Z
I( X ,Y ,Z ) =Y ^ ( X | (~Z) )
(&是与(And),|是或(Or),~是非(Not),^是异或(Xor))
| & | 与 | 两个位都为1时,结果才为1 |
| | | 或 | 两个位都为0时,结果才为0 |
| ^ | 异或 | 两个位相同为0,相异为1 |
| ~ | 取反 | 0变1,1变0 |
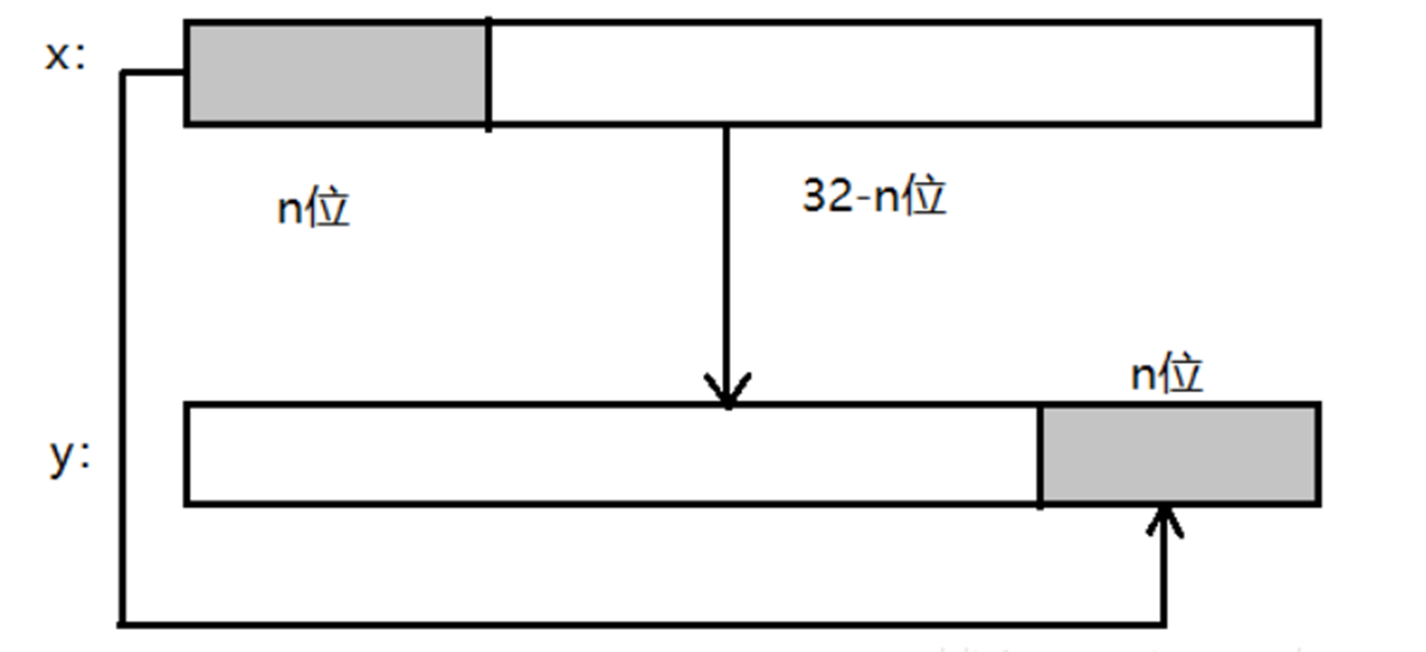
| <<< | 循环左移 | 将移出的低位放到该数的高位 |
循环左移:
这四个函数的说明:如果X、Y和Z的对应位是独立和均匀的,那么结果的每一位也应是独立和均匀的。
F是一个逐位运算的函数。即,如果X,那么Y,否则Z。函数H是逐位奇偶操作符。
假设Mj表示消息的第j个子分组(从0到15),常数ti是4294967296*abs( sin(i) )的整数部分,i 取值从1到64,单位是弧度。(4294967296=2^(32))
注意:“<<<”表示循环左移位,不是左移位
K表
1 | [0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee, 0xf57c0faf, |
所有这些完成之后,将a、b、c、d分别在原来基础上再加上A、B、C、D。
即a = a + A,b = b + B,c = c + C,d = d + D
然后用下一分组数据继续运行以上算法。
输出
最后的输出是a、b、c和d的大端法级联。
例子:123456 进行md5
123456==>ASCII 31 32 33 34 35 36
转为二进制就是 4*12 = 48bit
31 ==> 0011 0001
32 ==> 0011 0010
33 ==> 0011 0011
34 ==> 0011 0100
35 ==> 0011 0101
36 ==> 0011 0110
48bit填充1000….到448bit 填充1个1和399个0
0011 0001 0011 0010 0011 0011 0011 0100 0011 0101 0011 0110 1000000….
对应16进制
31 32 33 34 35 36 80 …..(98个0)
512bit - 448bit = 64bit
留的那64比特长度,用于填充长度信息,长度单位为比特
64bit附加长度信息 (就是明文对应16进制的长度)
00 …. 48(60个0)以小端法存放==》 48 00 … 00
明文48bit+填充(10…)400bit+长度信息(48 00..)64bit = 512bit
31 32 33 34 35 36 80 00 … 30 00 ..
512bit / 4 = 128位16进制
128分16组 = 8位 (每组8位)
M1 ==> 31 32 33 34
M2 ==> 35 36 80 00
M3 ==> 00 00 00 00
…
M15 ==> 30 00 00 00
M16 ==> 00 00 00 00
初始值变量
A=0x 01 23 45 67,
B=0x 89 AB CD EF,
C=0x FE DC BA 98,
D=0x 76 54 32 10。
以小端法存储
A ==> 0x 67 45 23 01
B ==> 0x EF CD AB 89
C ==> 0x 98 BA DC FE
D ==> 0x 10 32 54 76
二进制
A => 0110 0111 0100 0101 0011 0010 0000 0001
B => 1110 1111 1100 1101 1010 1011 1000 1001
C => 1001 1000 1011 1010 1101 1100 1111 1110
D => 0001 0000 0011 0010 0101 0100 0111 0110
第一轮第一步
FF(a ,b ,c ,d ,M0 ,7 ,0xd76aa478 )
b + ( (a + F(b,c,d) + Mj + Ki) << s)
F(b,c,d) == > ( X & Y ) | ( (~X) & Z ) ==> If X then Y else Z
F(b,c,d) ==> 1001 1000 1011 1010 1101 1100 1111 1110 ==> 98 BA DC FE
+a => 98 BA DC FE + 67 45 23 01 => FF FF FF FF
M1 = 31 32 33 34 小端法 => 34 33 32 31
+M1 => FF FF FF FF + 34 33 32 31 => 34 33 32 30 (只保留低8位)
+Ki==> 34 33 32 30 + D7 6A A4 78 => 0B 9D D6 A8 ==> 0000 1011 1001 1101 1101 0110 1010 1000
<<<s(7)
==> 0011 1011 1010 1101 0101 0000 0001 0111 ==> CE EB 54 05
+b
==> CE EB 54 05 + EF CD AB 89 ==> BE B8 FF 8E
第一轮后
a ==> 0x 10 32 54 76
b ==> 0x DE B8 FF 8E
c ==> 0x EF CD AB 89
d ==> 0x 98 BA DC FE
…
第64轮
a ==> 0x B7 E8 71 AF ==> 1011 0111 1110 1000 0111 0001 1010 1111
b ==> 0x BF 25 79 C0 ==> 1011 1111 0010 0101 0111 1001 1100 0000
c ==> 0x 2E 55 BB 7C ==> 0010 1110 0101 0101 1011 1011 0111 1100
d ==> 0x D2 96 E7 E0 ==> 1101 0010 1001 0110 1110 0111 1110 0000
b + ( (a + I(b,c,d) + Mj + ti) << s)
I(b,c,d) ==> I( b ,c ,d ) =c ^ ( b | (d) ) ==> d) ==> 0010 1101 0110 1001 0001 1000 0001 1111
(
b | (~d) ==> 1011 1111 0110 1101 0111 1001 1101 1111
c ^ ( b | (~d) ) ==> 1001 0001 0011 1000 1100 0010 1010 0011 ==> 91 38 C2 A3
+a ==> 0x 49 21 34 52
M64 = 0
+M64 ==> 0x 49 21 34 52
K64 = 0x EB 86 D3 91
+K64 ==> 0x 34 A8 07 E3 ==> 0011 0100 1010 1000 0000 0111 1110 0011
s64 = 21
<< s ==> 1111 1100 0110 0110 1001 0101 0000 0000 ==> 0x FC 66 95 00
+b ==> 0x BB 8C 0E C0
a == d ==0x D2 96 E7 E0
b ==0x BB 8C 0E C0
c == b ==0x BF 25 79 C0
d == c ==0x 2E 55 BB 7C
将a、b、c、d分别在原来基础上再加上A、B、C、D。
即a = a + A,b = b + B,c = c + C,d = d + D
a = a + A ==> 0x 39 DC 0A E1 ==> 0x E1 0A DC 39
b = b + B ==> 0x AB 59 BA 49 ==> 0x 49 BA 59 AB
c = c + C ==> 0x 57 E0 56 BE ==> 0x BE 56 E0 57
d = d + D ==>0x 3E 88 0F F2 ==> 0x F2 0F 88 3E
abcd == E1 0A DC 39 49 BA 59 AB BE 56 E0 57 F2 0F 88 3E => e10adc3949ba59abbe56e057f20f883e
MD5相对MD4所作的改进:
1.增加了第四轮.
2.每一步均有唯一的加法常数.
3.为减弱第二轮中函数G的对称性从(X&Y)|(X&Z)|(Y&Z)变为(X&Z)|(Y&(~Z))
4.第一步加上了上一步的结果,这将引起更快的雪崩效应.
5.改变了第二轮和第三轮中访问消息子分组的次序,使其更不相似.
6.近似优化了每一轮中的循环左移位移量以实现更快的雪崩效应.各轮的位移量互不相同.
对明文编码

为什么是这些非线性函数?
Ø这没什么最优解,你也可以使用别的非线性函数,或者自己实现时把顺序颠倒
Ø但这可能会造成算法安全性下降,而且是你无法把控的部分,因为这部分内容的专业性非常强,属于密码学的内容
为什么K表是这样,sin函数,或者说三角函数,在这儿扮演了怎样的角色?
k表的生成是: Ki = 2^32 x |sin i|
截取整数转16进制
例如:K1 = 2^32 x |sin 1| = 3614090360.2828…..
3614090360 ==> D76AA478
循环左移为什么是这样移?这个规定是为什么呢?(随机)
我们只知道,本质上,它是为了更好的扩散和混淆,让明文和密文之间没有明显的对应和关联,但为什么这样做,可能是安全性上的考量
比如胎死腹中的sha0和被广泛使用的sha1,竟然只通过循环左移1位就解决了安全性的问题
为什么是填充1个1和其余都是0,不是都是0
加入输入 1000
填充都是0后 1000 0000
不知道明文是哪个了
填充1后 1000 1000
就可以区分出来
大端、小端基础知识
https://zhuanlan.zhihu.com/p/316347205

python md5
1 | import binascii |