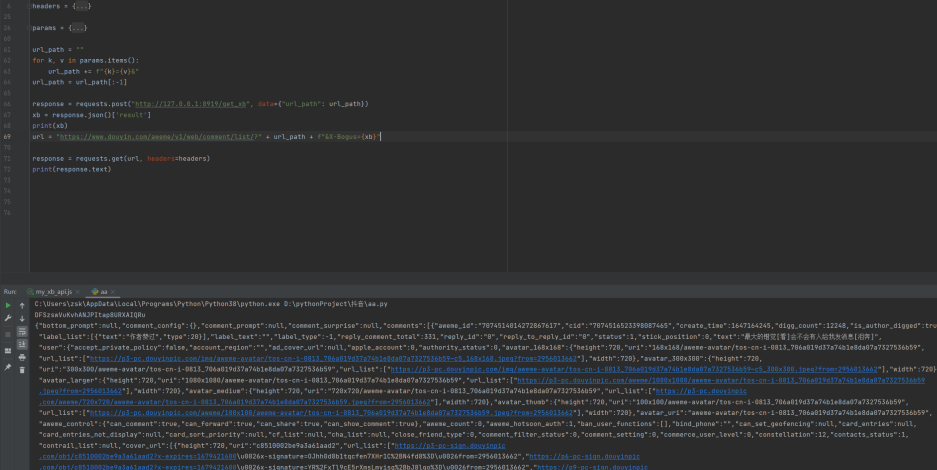
目标:视频评论接口X-Bogus参数
接口地址:’aHR0cHM6Ly93d3cuZG91eWluLmNvbS9hd2VtZS92MS93ZWIvY29tbWVudC9saXN0Lw==’
抓包
该接口是xhr请求,使用xhr下断点,当url中包含X-Bogus时就断下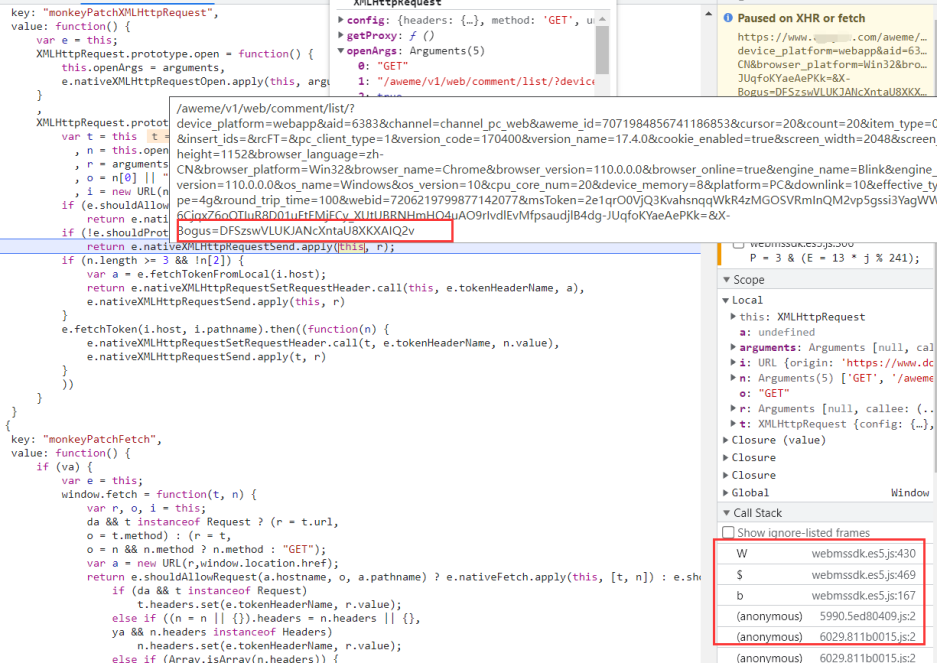
看调用栈上一层是在webmssdk.es5.js文件里,其实这个文件就是生成参数的,通过查阅知道这就是jsvmp,而且整体上也做了混淆。
这里使用v_jstools插件进行变量的压缩计算。
还原后使用浏览器的 Overrides 替换功能将 webmssdk.es5.js替换掉。
往上跟栈也就是跟到上图的堆栈b那里,X-Bogus参数是在this.openArgs[1]里面,直接打一个条件断点在b那this.openArgs[1].indexOf("X-Bogus") != -1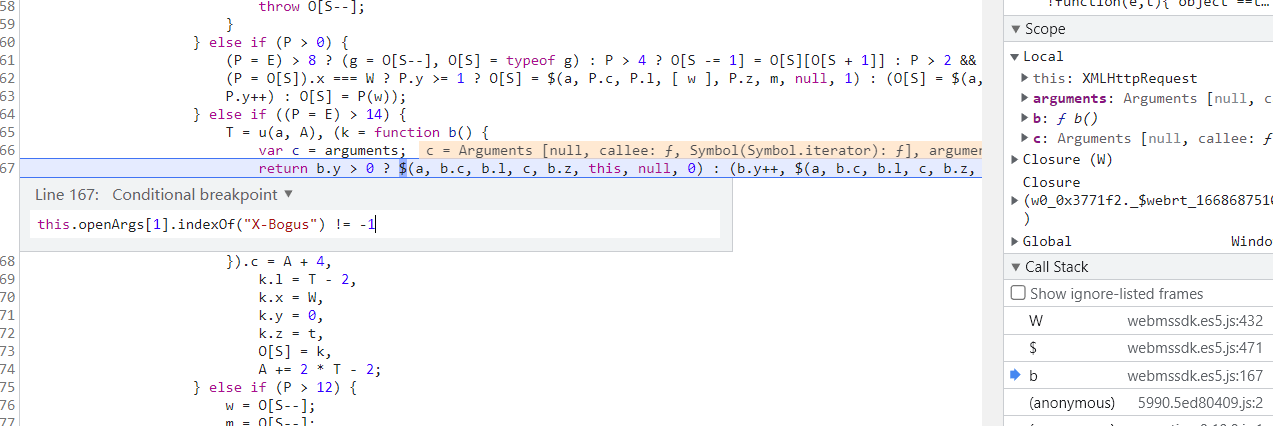
翻页评论重新触发请求,如图所示,到这里就已经生成了X-Bogus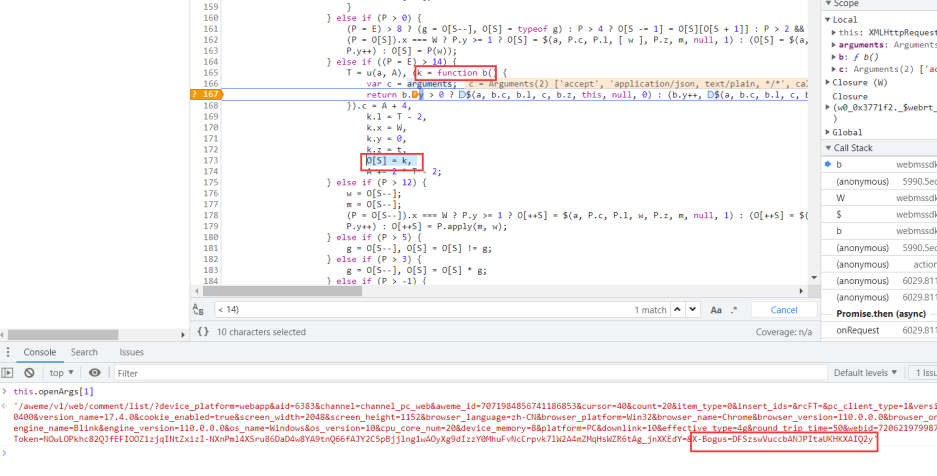
如图所示,$函数这里就已经生成了X-Bogus,this.openArgs[1]就是携带了xb的完整url
仔细观察这段代码,有很多三元表达式,当 M 的值为 15 时,就会走到这段逻辑,执行完函数后赋值给K,K 的值生成之后,有一个 O[S] = K 的操作。
再往上看代码,O初始化的地方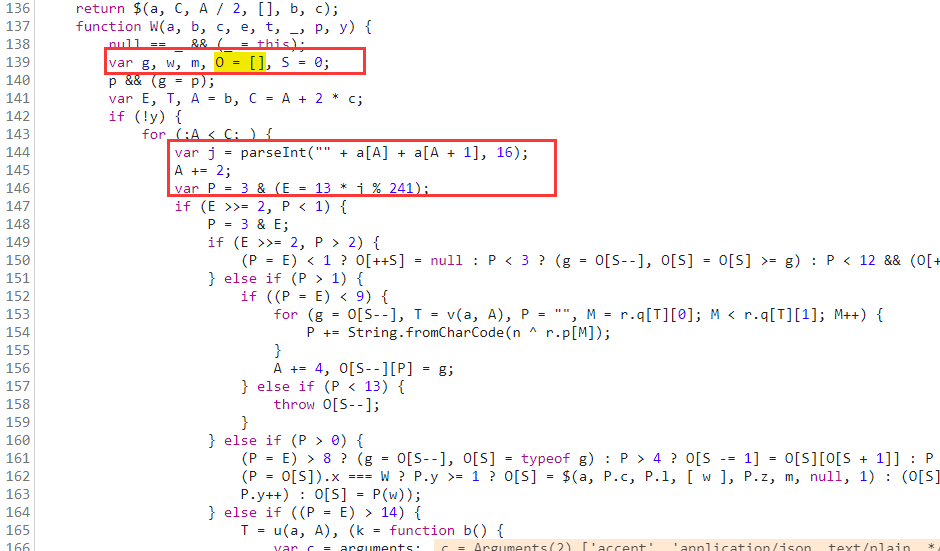
O 是一个数组,单步调试的话会发现代码会一直走这个 if-else 的逻辑,几乎每一步都有 O 数组的参与,不断往里面增删改查值,for 循环里面的 j 值,决定着后续 if 语句的走向,这里也就是插桩的关键所在。
插桩分析
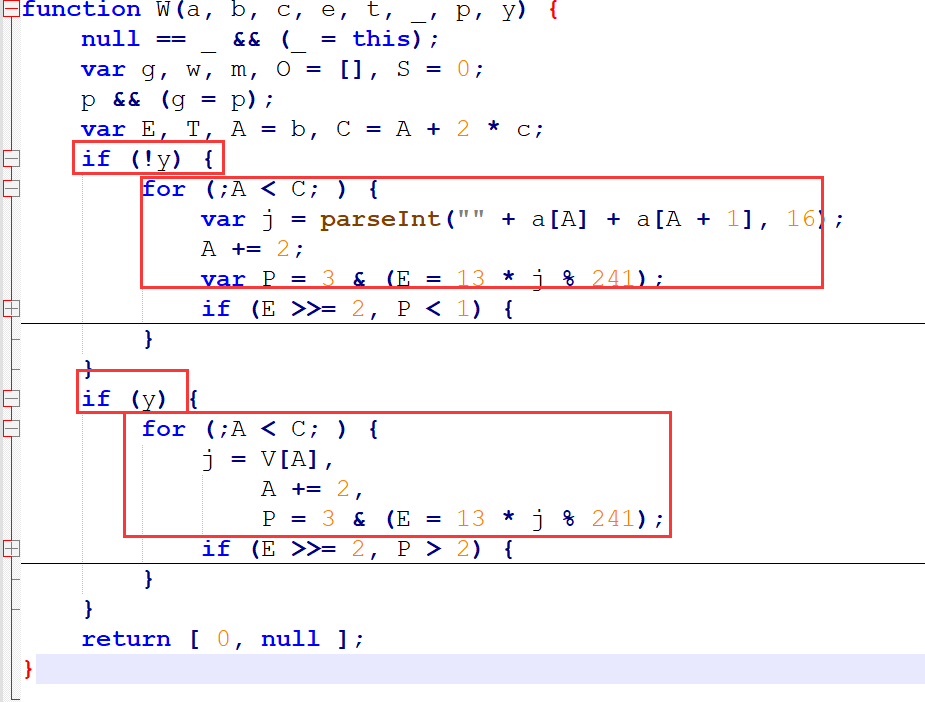
大的 for 循环和 if-else 逻辑有两个地方,为了保证最后的日志更加详细完整,在这两个地方都下个日志断点(右键 Add logpoint),断点内容为:
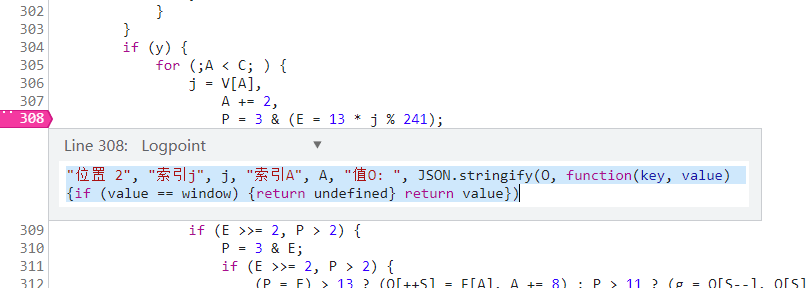
“位置 1”, “索引j”, j, “索引A”, A, “值O: “, JSON.stringify(O, function(key, value) {if (value == window) {return undefined} return value})
“位置 2”, “索引j”, j, “索引A”, A, “值O: “, JSON.stringify(O, function(key, value) {if (value == window) {return undefined} return value})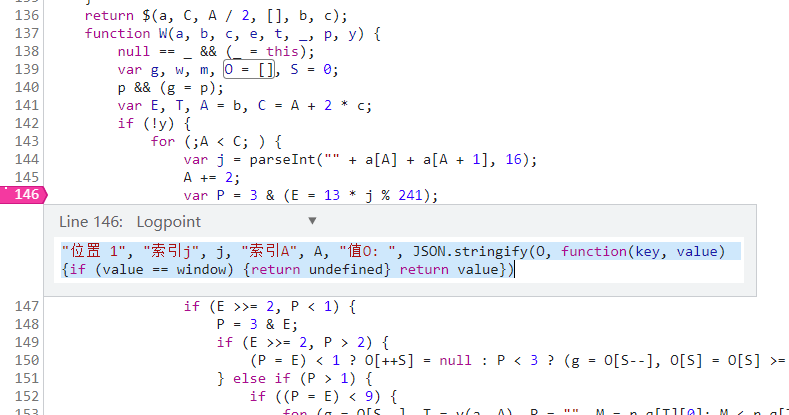
插桩输出 O 的时候为什么要写这么长一串呢?首先 JSON.stringify() 方法的作用是将 JavaScript 值转换为 JSON 字符串,基础语法是 JSON.stringify(value[, replacer [, space]]),如果不将其转换成 JSON,那么 O 的值,输出可能是这样的:[empty, Array(26), 1, Array(0)],你看不到 Array 数组里面具体的值,该方法有个可选参数 replacer,如果 replacer 为函数,则 JSON.stringify 将调用该函数,并传入每个成员的键和值,在函数中可以对成员进行处理,最后返回处理后的值,如果此函数返回 undefined,则排除该成员。
下好日志断点后,注意前面我们下的 XHR 断点不要取消,然后进行翻页出发请求,控制台就开始打印日志了,如果 XHR 断点取消了,日志就会一直打印直到卡死。日志输出完毕后,右键Save as保存下来到本地进行分析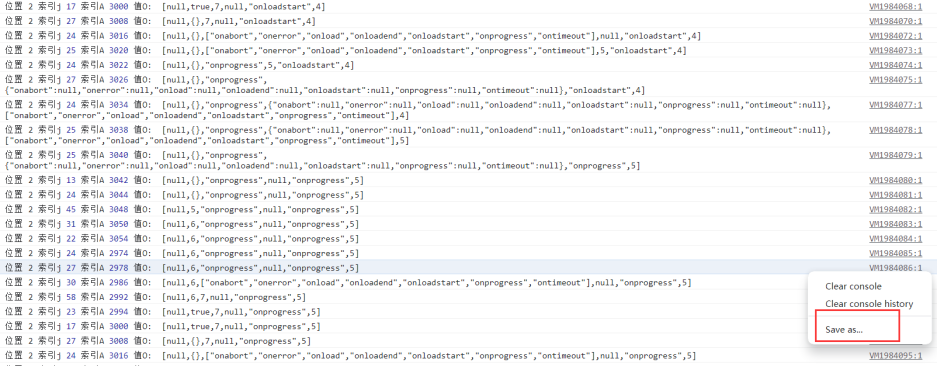
顺便记录下当前已经生成的xb,DFSzswVupV0ANJPItap8URXAIQ5f
xb由DFSzswVupV0ANJPItap8URXAIQ5f这28位字符组成的,现在看是怎么来的,打开刚才的日志,在里面搜索,找到第一次出现的地方。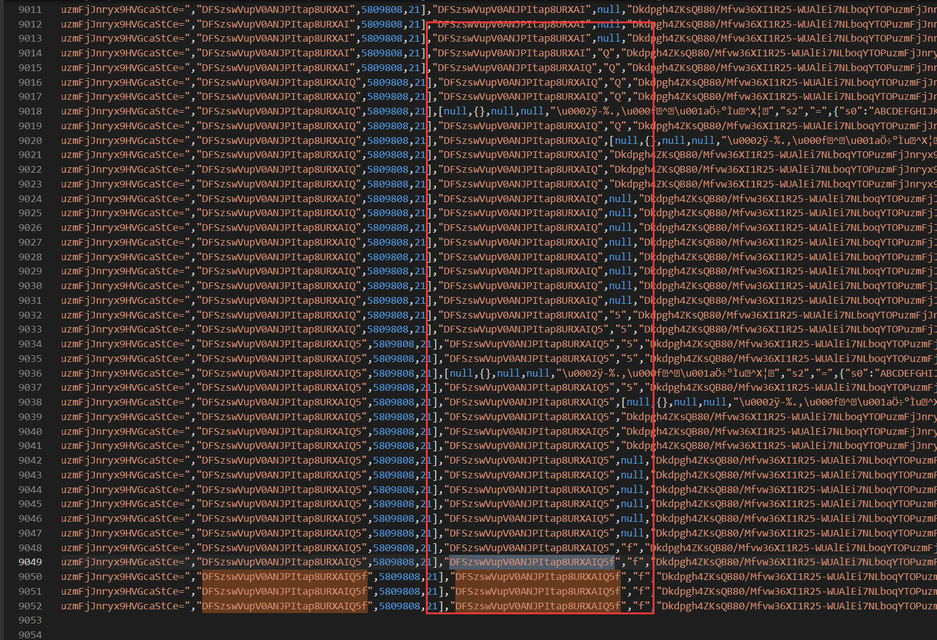
可以看到是逐个生成的,在9047行,xb后面的元素是null,到了下一行9048就生了下一个字符f,那么在这两步之间就是f的生成逻辑,这个时候我们看第9047行的日志断点是 位置 2 索引j 16 索引A 716,那么我们回到原网页,在位置2,下一个条件断点(右键 Add conditional breakpoint),当 j==16 && A==716 && O[7] == 21 时就断下。之所以要加 O[7] 是因为 索引j 16 索引A 716 的位置有很多,多加个限制条件就可以缩小范围,当然有可能加了多个条件仍然有多个位置都满足,就需要自己筛选了,通过断点断下的时候看看控制台前面输出的日志来判断是不是我们想要的位置。
继续翻页,断下之后开始单步跟,来到下图所示的地方: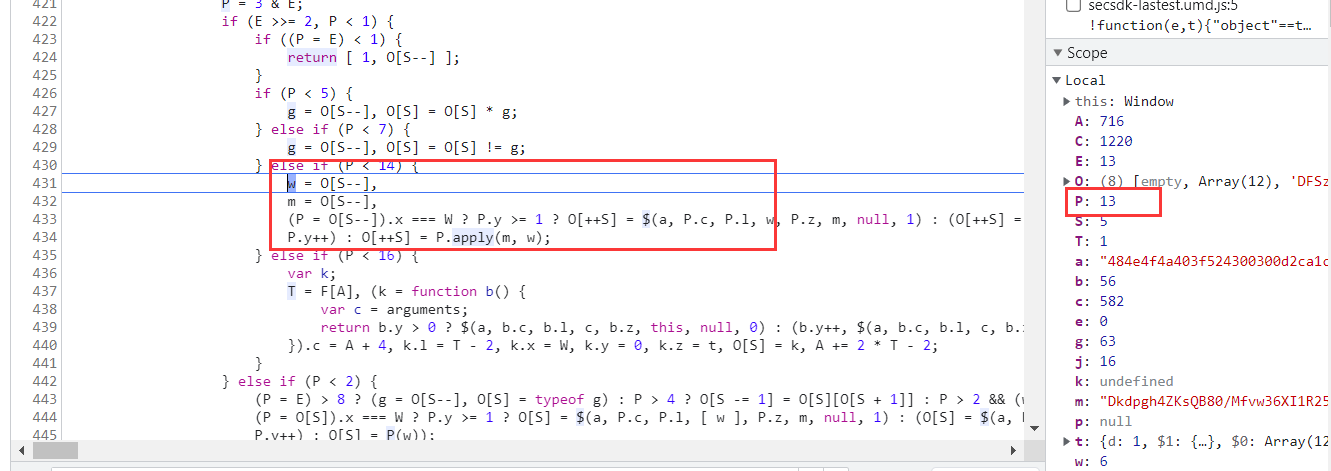
到这里之后,就不要下一步了,再下一步有可能整个语句就执行完毕了,其中的细节你看不到,所以这里我们在控制台挨个输入看看: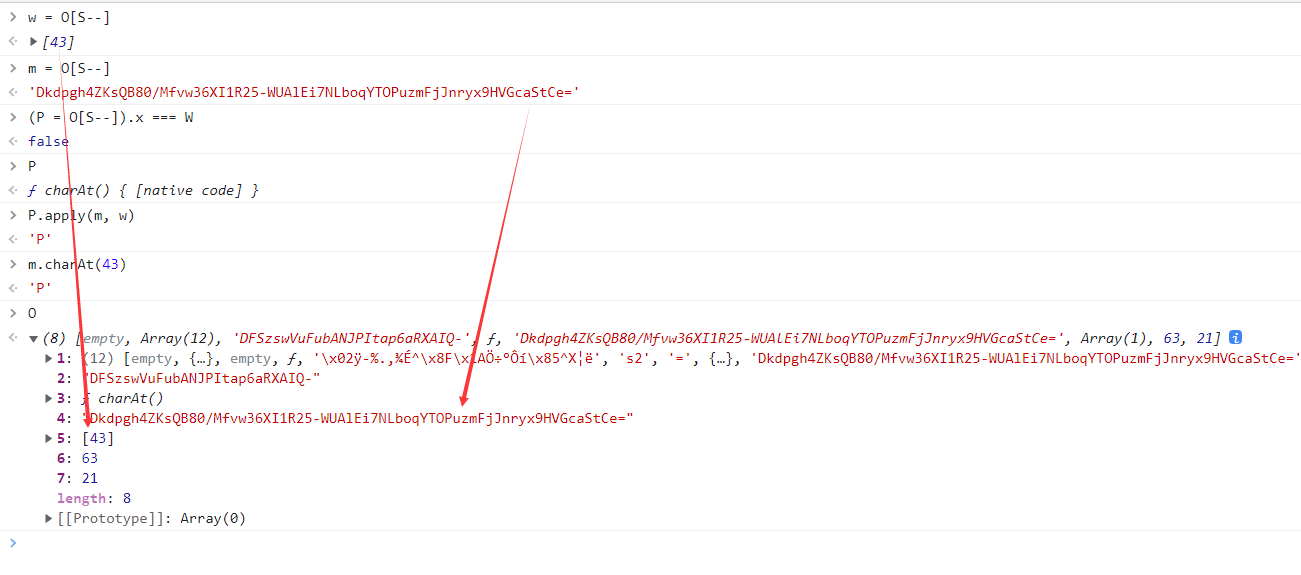
可以看到实际上的逻辑就是返回指定位置的字符,w 的值就是 O[5],m 的值就是 O[4],经过多次调试发现 m 的值是固定的,P 就是 charAt() 方法。我们再看看我们本地的日志,O[5] 的值为 [16],charAt() 取值出来就是f,逻辑完全正确。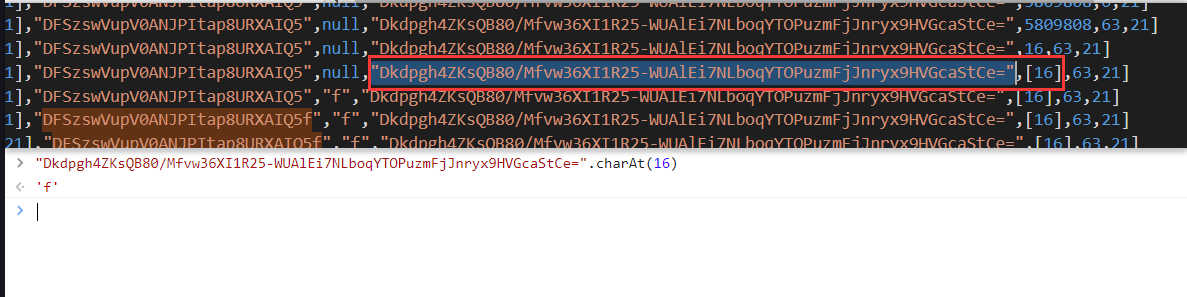
现在我们还需要知道这个16是怎么来的,继续往上看,找到16第一次出现的地方,在第9046行,那么我们就要使其在上一步断下,也就是第9045行,如下图所示:
第9045行的索引信息为 位置 2 索引j 47 索引A 708,同样的下条件断点观察怎么生成的: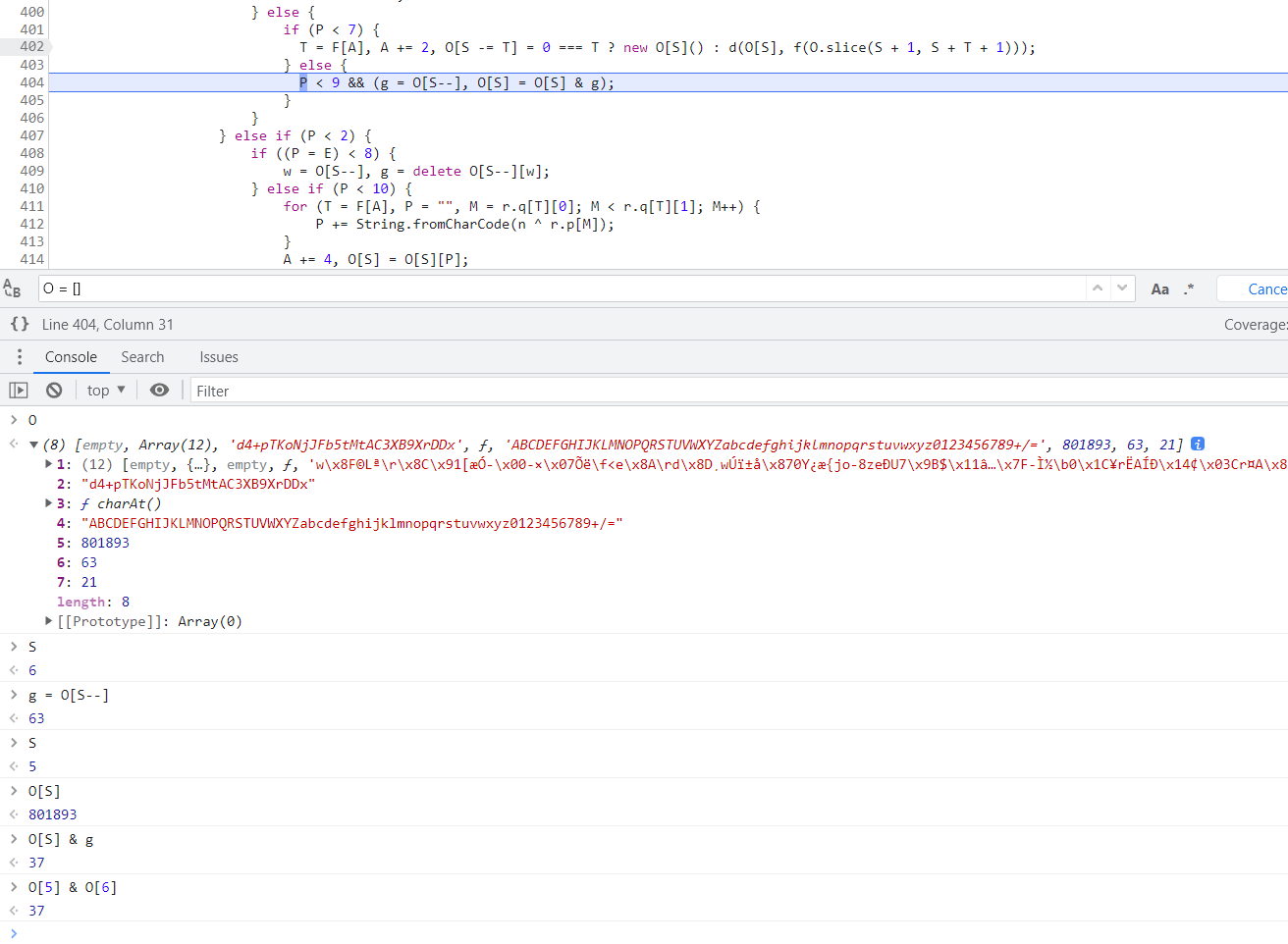
可以看到逻辑是 O[5] & O[6],再把值赋给O[5],再看我们之前本地的日志
O[5] = 5809808
O[6] = 63
5809808 & 63 = 16,逻辑正确,16就是这么来的。接下来又开始找 5809808 和 63 是怎么生成的,先看看63是怎么来的,同样在生成的上一步,也就是第9044行下个条件断点,这行的索引为 位置 2 索引j 72 索引A 704。
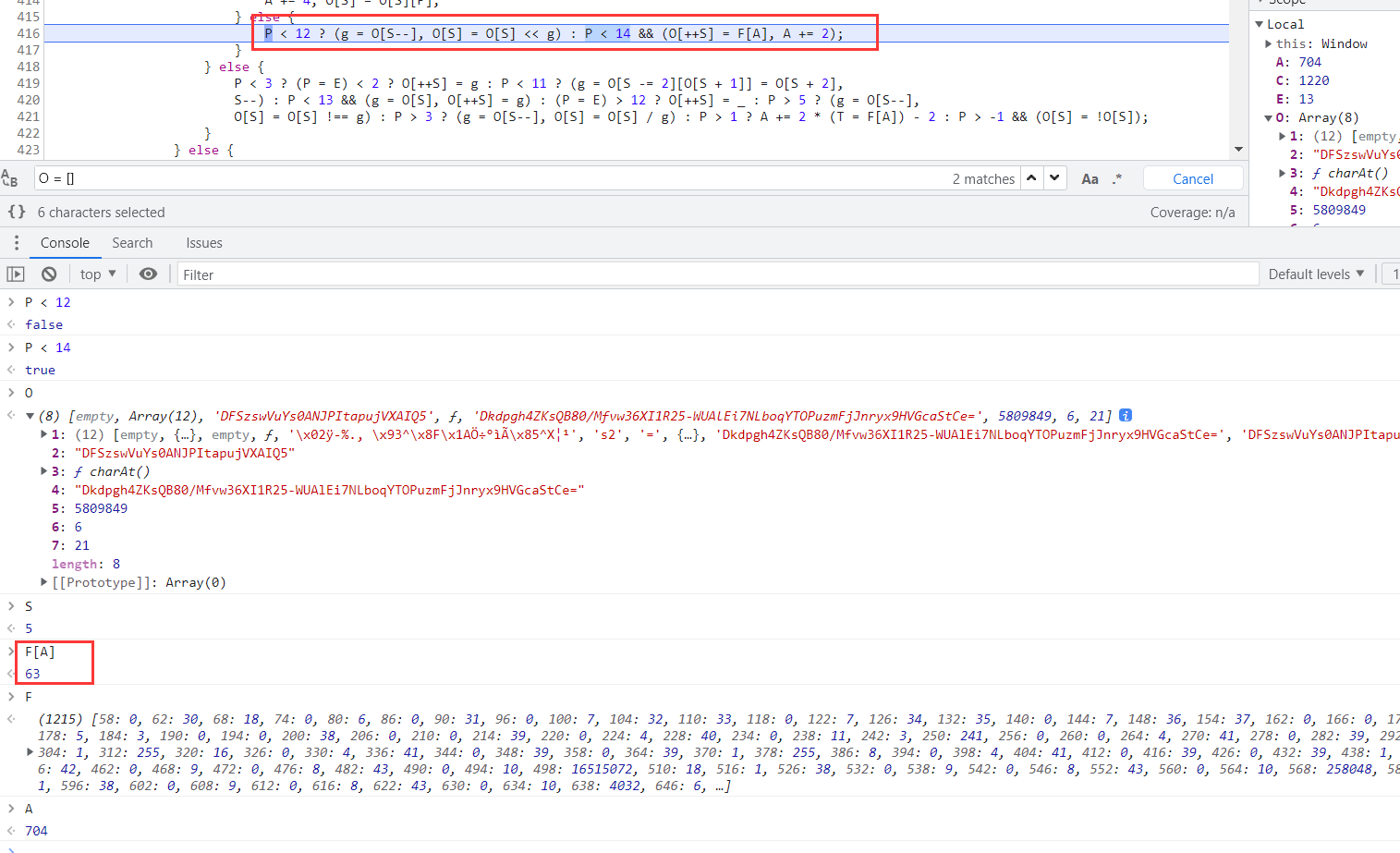
可以看到 63 是直接 F[A] 生成的,F 是一个大数组,A 就是索引为 704,F 这个大数组怎么来的先不用管,经过几次测试发现是固定的。
5809808后面再说,再逐个找倒数的字符串的生成,记录下来
xb = “DFSzswVupV0ANJPItap8URXAIQ5f”
m = “Dkdpgh4ZKsQB80/Mfvw36XI1R25-WUAlEi7NLboqYTOPuzmFjJnryx9HVGcaStCe=”
第28字符串 ==> f=m[16],16=5809808&63,63=F[704]
第27字符串 ==> 5=m[26],26=1664>>6,6=F[646]
第26字符串 ==> Q=m[10],10=40960>>12,12=F[580]
第25字符串 ==> I=m[22],22=5767168>>18,18=F[510]
第24字符串 ==> A=m[30],30=7701854&63,63=F[704]
第23字符串 ==> X=m[21],21=1344>>6,6=F[646]
第22字符串 ==> R=m[24],24=98304>>12,12=F[580]
第21字符串 ==> U=m[29],29=7602176>>18,18=F[510]
第20字符串 ==> 8=m[12],12=16232652&63,63=F[704]
把xb = DFSz swVu pV0A NJPI tap8 URXA IQ5f,将其看成每四个为一组,从上面的规律可以得到,每4个字符串为一组,每组的字符生成流程都是一样的
就差大数字是怎么来的,搜本地日志5809808第一次出现的位置,x直接定位到第一次出现的地方第8979行的上一行第8978行,位置 2 索引j 48 索引A 454
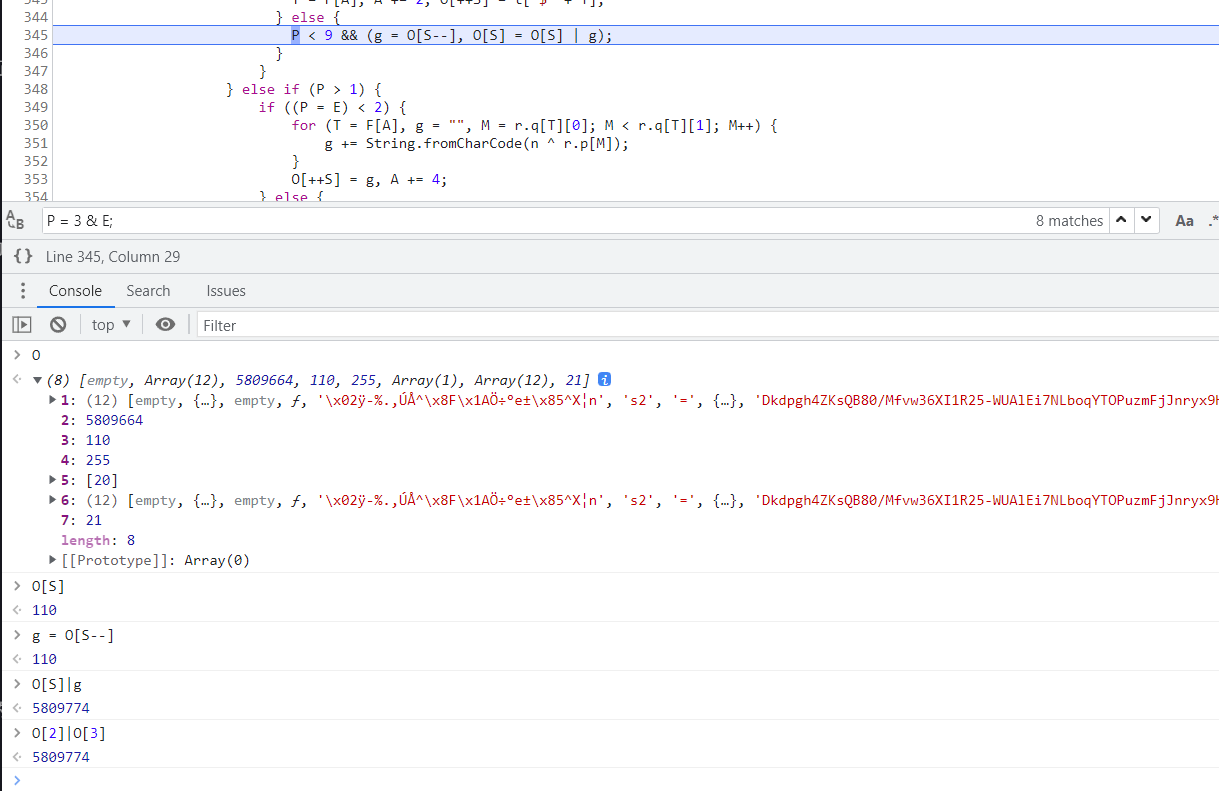
可以看出大数字是O[2]|O[3]计算而来,那我们本地5809808就是5809664|144
找到144第一次出现的地方,同样的操作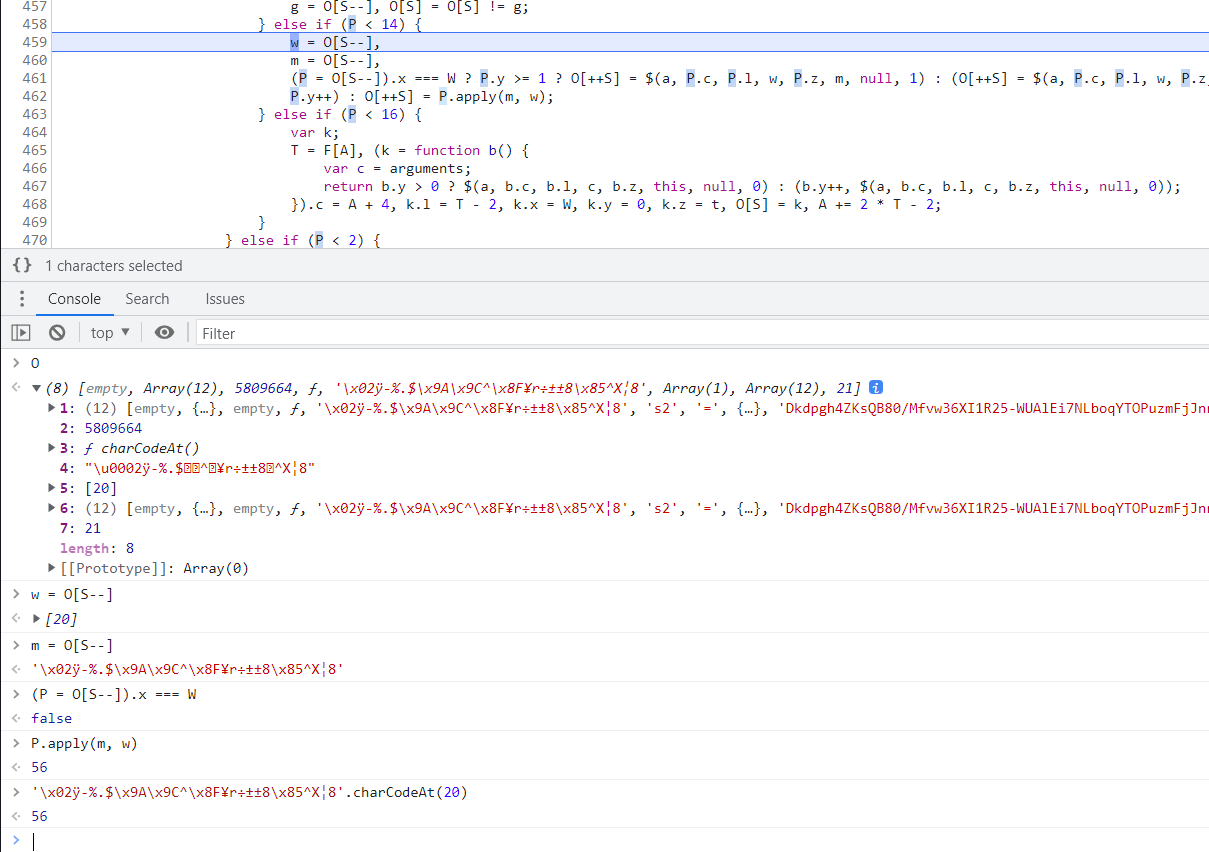
114是由O[4].charCodeAt(O[5])生成,O[4]=’\x02ÿ-%.,2\x10^\x8F\x1AÖ÷°cÛ\x85^X¦?’,O[5]=20
经过几次测试知道乱码字符串是跟url有关,生成过程后面说。用我们本地的O[4]试一下
“\u0002ÿ-%.,\u000F^\u001AÖ÷°Ìu
^X¦”.charCodeAt(20)
经过后面8位字符的跟进后,记录了一下规则
xb = “DFSzswVupV0ANJPItap8URXAIQ5f”
m = “Dkdpgh4ZKsQB80/Mfvw36XI1R25-WUAlEi7NLboqYTOPuzmFjJnryx9HVGcaStCe=”
第28字符串f:
f=m[16]
16=5809808&63
63=F[704]
5809808=5809664|144
144=”\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu ^X¦”.charCodeAt(20)
5809664=5767168|42496
42496=166<<8
8=F[386]
166=”\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu ^X¦”.charCodeAt(19)
5767168=88<<16
16=F[320]
88=”\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu ^X¦”.charCodeAt(18)第27字符串5:
5=m[26]
26=1664>>6
6=F[646]
1664=5809808&4032
4032=F[638]第26字符串Q:
Q=m[10]
10=40960>>12
12=F[580]
40960=5809808&258048
258048=F[568]第25字符串I:
I=m[22]
22=5767168>>18
18=F[510]
5767168=5809808&16515072
16515072=F[498]第24字符串A:
A=m[30]
30=7701854&63
63=F[704]
7701854=7701760|94
94=”\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu ^X¦”.charCodeAt(17)
7701760=7667712|34048
34048=133<<8
8=F[386]
133=”\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu ^X¦”.charCodeAt(16)
7667712=117<<16
16=F[320]
117=”\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu ^X¦”.charCodeAt(15)第23字符串X:
X=m[21]
21=1344>>6
6=F[646]
1344=7701854&4032
4032=F[638]第22字符串R:
R=m[24]
24=98304>>12
12=F[580]
98304=7701854&258048
258048=F[568]第21字符串U:
U=m[29]
29=7602176>>18
18=F[510]
7602176=7701854&16515072
16515072=F[498]
正序整理了一下,大致的流程就是
m = “Dkdpgh4ZKsQB80/Mfvw36XI1R25-WUAlEi7NLboqYTOPuzmFjJnryx9HVGcaStCe=”
xb = “DFSz swVu pV0A NJPI tap8 URXA IQ5f”
===============第6组 URXA ===============
“\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu
^X¦”.charCodeAt(15) = 117
F[320] = 16
117 << 16 = 7667712
“\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu
^X¦”.charCodeAt(16) = 133
F[386] = 8
133 << 8 = 34048
7667712|34048 = 7701760
“\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu
^X¦”.charCodeAt(17) = 94
7701760 | 94 = 7701854
F[498] = 16515072
7701854 & 16515072 = 7602176
F[510] = 18
7602176 >> 18 = 29
m.charAt(29) = ‘U’
F[568] = 258048
7701854 & 258048 = 98304
F[580] = 12
98304 >> 12 = 24
m.charAt(24) = ‘R’
F[638] = 4032
7701854 & 4032 = 1344
F[646] = 6
1344 >> 6 = 21
m.charAt(21) = ‘X’
F[704] = 63
7701854 & 63 = 30
m.charAt(30) = ‘A’
===============第7组 IQ5f ===============
“\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu
^X¦”.charCodeAt(18) = 88
F[320] = 16
88 << 16 = 5767168
“\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu
^X¦”.charCodeAt(19) = 166
F[386] = 8
166 << 8 = 42496
5767168 | 42496 = 5809664
“\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu
^X¦”.charCodeAt(20) = 144
5809664 | 144 = 5809808
F[498] = 16515072
5809808 & 16515072 = 5767168
F[510] = 18
5767168 >> 18 = 22
m.charAt(22) = ‘I’
F[568] = 258048
5809808 & 258048 = 40960
F[580] = 12
40960 >> 12 = 10
m.charAt(10) = ‘Q’
F[638] = 4032
5809808 & 4032 = 1664
F[646] = 6
1664 >> 6 = 26
m.charAt(26) = ‘5’
F[704] = 63
5809808 & 63 = 16
m.charAt(16) = ‘f’
将流程对比一下就可以发现,每个步骤 F 里面的取值都是一样的,这个可以直接写死,不同之处就在于最开始的 charCodeAt() 操作,也就是返回乱码字符串指定位置字符的 Unicode 编码,第7组依次是 18、19、20,第6组依次是15、16、17,以此类推,第1组刚好是0、1、2,如下图所示: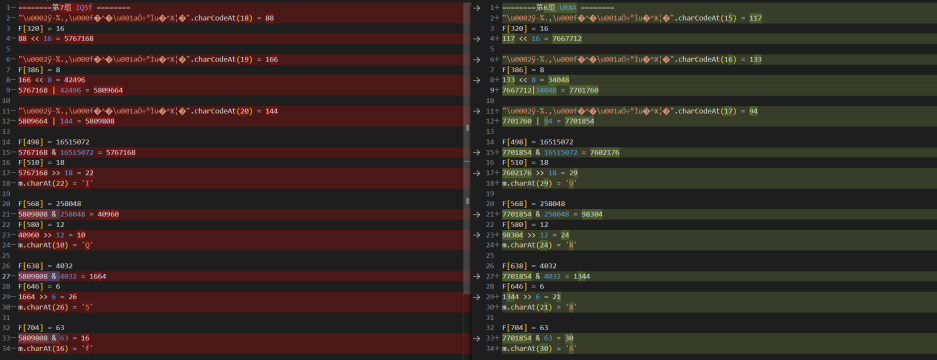
每一组的逻辑都是一样的,依次生成七组字符串,最后拼接成完整的 X-Bogus。
乱码字符串生成逻辑
该样本对应的param_url = “device_platform=webapp&aid=6383&channel=channel_pc_web&aweme_id=7071984856741186853&cursor=0&count=20&item_type=0&insert_ids=&rcFT=&pc_client_type=1&version_code=170400&version_name=17.4.0&cookie_enabled=true&screen_width=2048&screen_height=1152&browser_language=zh-CN&browser_platform=Win32&browser_name=Chrome&browser_version=110.0.0.0&browser_online=true&engine_name=Blink&engine_version=110.0.0.0&os_name=Windows&os_version=10&cpu_core_num=20&device_memory=8&platform=PC&downlink=3.85&effective_type=4g&round_trip_time=100&webid=7206219799877142077&msToken=Z9-0y9elP0-Obz51QiLXg2qpd-dyJHammHH_0hNY48UFC3RxAx8bjxf2Hpmxmm52cmDQVfBP0lf1UwzvAtbOcW6RGQuSY_1W-plCkw-lP-OkNH00Ion2DohnZlsySAc=”
在进行下一步之前,我们要注意两点:
- 文章演示有些变量前后不对应,因为每次插桩的值都是会变的,看流程就行了,流程是正确的;
- 我们日志输出是经过 JSON.stringify 处理了的,有些步骤是向某个函数传入乱码字符串进行处理,你会发现处理后的结果和日志不一致,这是正常的。
乱码字符串的生成相对来说稍微复杂一点,但思路仍然一样,这里就不一一截图展示了,直接用日志描述一下关键步骤,注意以下日志是正向的步骤,就不逆着推了,建议自己先逆着把流程走一走,再来看这个步骤就看得懂了。
Step1:首先对 URL 后面的参数,也就是 Query String Parameters 进行两次 MD5、两次转 Uint8Array 处理,最后得到的 Uint8Array 对象在后面的步骤中用得到,步骤如下:
位置 1 索引j 4 索引A 134:将 URL 后面的参数进行 MD5 加密得到字符串
位置 1 索引j 16 索引A 494:将上一步的字符串转换为 Uint8Array 对象
位置 1 索引j 4 索引A 134:将上一步的 Uint8Array 对象进行 MD5 加密,得到字符串
位置 1 索引j 16 索引A 504:将上一步的字符串转换为 Uint8Array 对象
上述步骤中,我们将最终得到的结果命名为 uint8Array,md5字符串转uint8Array,跟进到相应位置把函数抠出来即可
Step2:生成两个大数,一个是时间戳,我们称之为 fixedString1,另一个调用某个方法生成,我们称之为 fixedString2。
fixedString1
位置 1 索引j 43 索引A 1032:1677985818608 / 1000 = 1677985818.608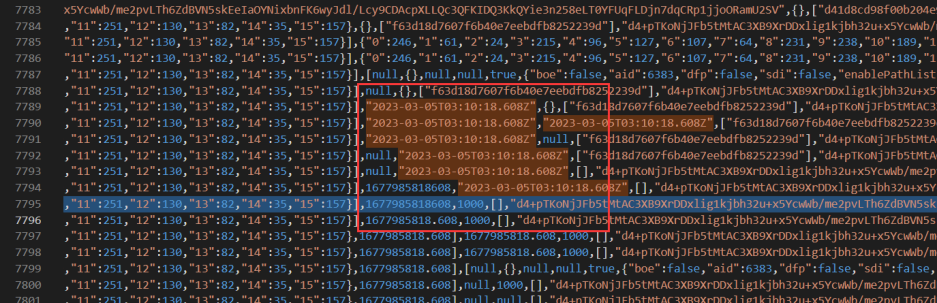
fixedString2
位置 1 索引j 16 索引A 1060:P.apply(null, []) = 1489154074
上述步骤中,P 对应以下方法,缺失的方法自行补齐:
1 | function _0x17dd8c() { |
Step3:先后生成两个数组,我们称之为 array1、array2,array2 就是由 array1 的元素位置变换后得来的,严格来讲,array1 不是一个完整的数组,而是一个个数字,这一点可以在日志中体现出来,为了方便我们就直接将其视为一个数组,两个数组都有19个元素,步骤如下:
array1[0] 至 array1[3] 为定值 [64,0.00390625,1,8]
array1[4]
位置 1 索引j 25 索引A 1172:uint8Array[14] = 127
array1[5]
位置 1 索引j 25 索引A 1196:uint8Array[15] = 208
array1[6]、array1[7] 可以直接写死
array1[8]、array1[9] 与 ua 有关, 可以直接写死
array1[10]
位置 1 索引j 52 索引A 1316:fixedString1 >> 24 = 100
位置 1 索引j 47 索引A 1324:100 & 255 = 100
array1[11]
位置 1 索引j 52 索引A 1348:fixedString1 >> 16 = 25604
位置 1 索引j 47 索引A 1356:25604 & 255 = 4
array1[12]
位置 1 索引j 52 索引A 1380:fixedString1 >> 8 = 6554632
位置 1 索引j 47 索引A 1388:6554632 & 255 = 8
array1[13]
位置 1 索引j 52 索引A 1412:fixedString1 >> 0 = 1677985818
位置 1 索引j 47 索引A 1420:1677985818 & 255 = 26
array1[14]
位置 1 索引j 52 索引A 1444:fixedString2 >> 24 = 88
位置 1 索引j 47 索引A 1452 :88 & 255 = 88
array1[15]
位置 1 索引j 52 索引A 1476:fixedString2 >> 16 = 22722
位置 1 索引j 47 索引A 1484:22722 & 255 = 194
array1[16]
位置 1 索引j 52 索引A 1508:fixedString2 >> 8 = 5817008
位置 1 索引j 47 索引A 1516:5817008 & 255 = 176
array1[17]
位置 1 索引j 52 索引A 1540:fixedString2 >> 0 = 1489154074
位置 1 索引j 47 索引A 1548:1489154074 & 255 = 26
array1[18]
前面18个字符全部进行亦或
位置 1 索引j 49 索引A 1736:array1.reduce(function(a, b) { return a ^ b; }); = 96
array1 完整值如下
位置 1 索引j 16 索引A 1932:
array1 = [64,0.00390625,1,8,127,208,69,63,35,157,100,4,8,26,88,194,176,26,96]
array2 由 array1 元素交换位置而来:
array2 = [array1[0], array1[2], array1[4], array1[6], array1[8], array1[10], array1[12], array1[14], array1[16], array1[18], array1[1], array1[3], array1[5], array1[7], array1[9], array1[11], array1[13], array1[15], array1[17]]
array2 完整值如下
array2 = [64, 1, 127, 69, 35, 100, 8, 88, 176, 96, 0.00390625, 8, 208, 63, 157, 4, 26, 194, 26]
Step4:将 Step3 得到的 array2 经过转换得到乱码字符串,步骤如下:
位置 1 索引j 16 索引A 1932: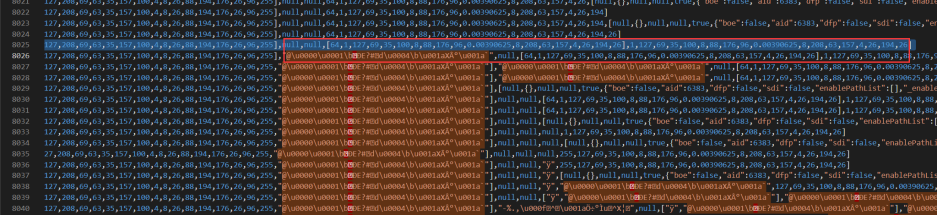
_0x398111.apply(null, array2) = ‘@\u0000\u0001\bÐE?#d\u0004\b\u001aX°\u001a`’
位置 1 索引j 16 索引A 1986:
_0x25788b.apply(null, [‘ÿ’,‘@\x00\x01\bïwE?#\x9Dd\x074\x89X°\x1Aû’]) = ‘-%.,\u000f^\u001aÖ÷°Ìu�^X¦’
位置 1 索引j 16 索引A 2038:
_0x94582.apply(null, [2,255,’-%.,\u000f^\u001aÖ÷°Ìu�^X¦’]) = “\u0002ÿ-%.,\u000f^\u001aÖ÷°Ìu�^X¦”
至此乱码字符串的流程就结束了。
以上缺的函数根据相应的索引根据到代码位置抠出来即可
测试成功,我这里把生成方式封装成api接口