
以下ARM笔记我基于 _周壑 大佬在b站的视频教程整理来的,推荐配合视频使用
环境搭建
arm文档下载链接:https://documentation-service.arm.com/static/644a406baa78c007af74e6fd?token=其中指令集在目录 F5.1 Alphabetical list of T32 and A32 base instruction set instructions。在android studio中创建设备,选择api17的,armeabi-v7a架构。创建后的设备默认路径在 C:\Users\zsk.android\avd,snapshots保存的是快照快捷方式启动设备: 创建bat文件,输入D:\Android\Sdk\emulator\emulator.exe -avd Pixel_XL_API_17_2,运行启动设备将ida的android-server push到设备上,android-server文件在ida目录下的dbgsrvpush后修改文件权限为777,运行,端口转发:adb forward tcp:23946 tcp:23946运行后就可以在ida选择设备调试,Debugger -> Attach -> Remote ARMLinux/Android debuggerhostname填localhost,没有进行端口转发则需要填手机ip,能看到进程列表则成功
c文件编译成arm运行
在window下把c文件编译为arm的前置准备hello.c
1 |
|
在同级目录下新建Application.mk,Android.mk文件https://developer.android.google.cn/ndk/guides/android_mk?hl=zh-cn
Application.mk
1 | APP_ABI := armeabi-v7a |
Android.mk
1 | LOCAL_PATH := $(call my-dir) |
编译,可以弄成bat方便执行
1 | ndk-build NDK_PROJECT_PATH=. NDK_APPLICATION_MK=Application.mk |
需要在Android studio中下载ndk工具,下载好后会在sdk下有ndk文件,进入选择随便一个版本路径配置环境变量运行显示过程[armeabi-v7a] Compile thumb : hello <= hello.c[armeabi-v7a] Executable : hello[armeabi-v7a] Install : hello => libs/armeabi-v7a/hello结束后会在目录生成obj和libs文件,在libs下是hello可执行文件,obj下是debugger版的可执行文件,调试的话就用obj下的。将文件push到手机,修改777权限,执行运行
1 | root@android:/data/local/tmp # chmod 777 hello |
这样一下子就运行玩完了,没法调试,修改代码让它一直运行
1 |
|
重新编译并推送执行
ida调试
回到ida,调试运行中的hello程序
避免每次都要执行多行命令,可以整合成一个bat
1 | adb push D:\Android\arm_test\obj\local\armeabi-v7a\hello /data/local/tmp/ |
寄存器和指令基本格式
没有隐式内存操作指令,
一条ARM汇编指令可以包含0到3个操作数。操作数是指执行指令时所涉及的数据或寄存器。内存操作数和里脊操作数不能同时存在,意味着在一条指令中,不能同时存在既是内存操作数又是寄存器操作数。你要么使用内存地址作为操作数,要么使用寄存器。内存操作数至多出现一次,寄存器操作数总在最前面
特殊情况:
- 读PC寄存器,arm读PC加8,thumb读PC加4
- C标志位使用
寄存器:
- 寄存器是计算机中一种高速的、临时的、可用于存储和操作数据的存储单元。在ARM架构中,通常使用 R0、R1、R2 等寄存器来表示通用寄存器。这些寄存器可以用来存储临时数据、地址或执行算术和逻辑运算。
立即数:
- 立即数是在指令中直接提供的常数值,而不是从内存中加载。在汇编语言中,可以使用 # 符号表示立即数。例如,在 MOV R0, #10 中,#10 就是一个立即数,表示将值 10 直接存储到寄存器 R0 中。
操作数:
- 操作数是参与运算的数据或者指令中的一个参数。在指令中,你可能会看到源操作数和目标操作数。在 MOV R0, #10 中,#10 是源操作数,表示移动的数据;而 R0 是目标操作数,表示数据要移动到的位置。
MOV:
- 用于将一个数值(立即数或寄存器中的值)移动到目标寄存器。 MOV R0, #10 ; 将立即数 10 移动到寄存器 R0 MOV R1, R2 ; 将寄存器 R2 中的值移动到寄存器 R1
基本运算:
- ADD:加法指令。
- ADR:将地址加载到寄存器的伪指令。
- SUB:减法指令。
- RSB:反向减法指令。
- AND:按位与运算指令。
- BIC:按位与非运算指令。
- ORR:按位或运算指令。
- EOR:按位异或运算指令。
- LSL:逻辑左移指令。
- LSR:逻辑右移指令。
- ASR:算术右移指令。
访存:
- LDR:从内存中加载数据到寄存器。
- STR:将寄存器中的数据存储到内存。
块访存:
- LDMFD:从内存中加载多个寄存器,然后递减栈指针。
- LDMIA:从内存中加载多个寄存器,然后递增基址寄存器。
- STMFD:将多个寄存器的值存储到内存,然后递减栈指针。
- STMIA:将多个寄存器的值存储到内存,然后递增基址寄存器。
分支:
- B:无条件分支。
- BL:带链接的无条件分支,用于函数调用。
- BX:无条件分支并切换指令集(ARM/Thumb)。
- BLX:带链接的无条件分支并切换指令集。
在ida中按ctrl+alt+k可以修改指令
条件和标志位响应
条件指令
 条件指令是加在运算符后面的,如何看懂?例如机器码为:03 00 10 E3 TST小端序排序的,前高4位是条件,看最高位也就是E,E的对应的bit为1110,也就是None,无条件,可以说E是出现最多的06 00 00 0A BEQ最高位0,0就是EQ,03 00 52 21 CMPCS最高位为2,2就是0010,CS指令后缀带S的,表示执行完标志位会改变01 00 80 E0 ADD R0, R0, R101 00 90 E0 ADDS R0, R0, R101 00 40 E0 SUB R0, R0, R101 00 50 E0 SUBS R0, R0, R1S是由第20个bit控制,也就是上面的8,9
条件指令是加在运算符后面的,如何看懂?例如机器码为:03 00 10 E3 TST小端序排序的,前高4位是条件,看最高位也就是E,E的对应的bit为1110,也就是None,无条件,可以说E是出现最多的06 00 00 0A BEQ最高位0,0就是EQ,03 00 52 21 CMPCS最高位为2,2就是0010,CS指令后缀带S的,表示执行完标志位会改变01 00 80 E0 ADD R0, R0, R101 00 90 E0 ADDS R0, R0, R101 00 40 E0 SUB R0, R0, R101 00 50 E0 SUBS R0, R0, R1S是由第20个bit控制,也就是上面的8,9

S位为0就是不带S,为就是S大部分算术指令都可以加S,CMP不行,CMP的20位固定为1
- 运算指令可以分为以下三种:
- 第一种既要结果又要标志寄存器,subs,adds
- 第二种只要结果,sub,add
- 第三种只要标志寄存器,cmp,cmn
MOV指令
立即数
Move(immediate)将立即数值写入目标寄存器。
mov是不访问内存,没有写内存的功能。那就只有寄存器操作数或者立即操作数mov是把第二个操作数(可能是寄存器也可能是立即数)写到第一个操作数,那第一个操作数只能是寄存器操作数arm指令是定长32位的,也就是立即数长度肯定不会超过32位
这里立即数的位数是imm4+imm12,也就是16位例如:34 82 01 E3 MOVW R8, #0x1234如果是超过16位,则写不进。第15-12位4位二进制的长度刚好16对应着r0-r15还有一种A1格式,立即数是可以超过16-32位的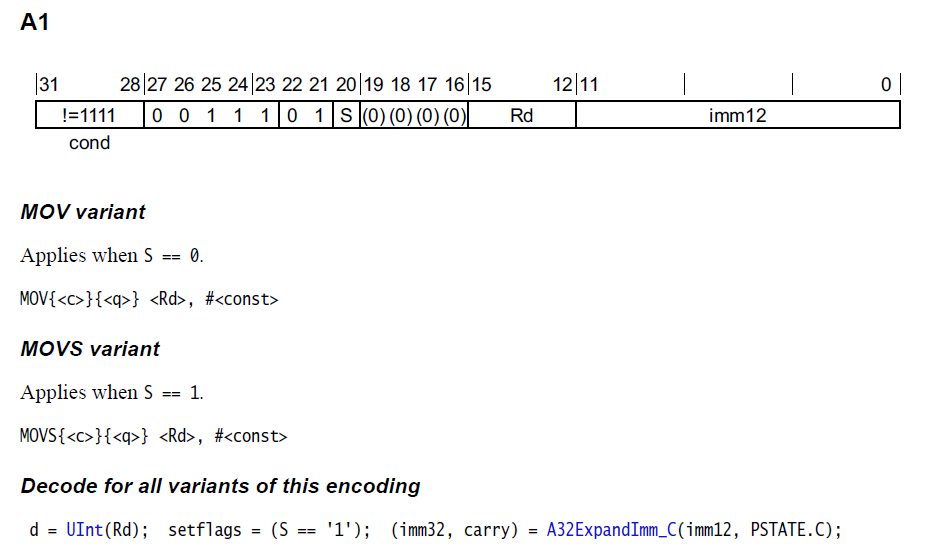
02 81 A0 E3 MOV R8, #0x80000000虽然这里长度比16位大,但是它的有效位只有最高位的8,这里是把2向右移动1*2位, 0010 ->右移2位-> 1000 -> 8(十进制)01 81 A0 E3 MOV R8, #0x40000000把1向右移动1*2位,0001 ->右移2位-> 0100 -> 4(十进制)02 82 A0 E3 MOV R8, #0x20000000把2向右移动4位,0010 ->右移4位-> 0010 -> 2(十进制)立即数的有效位数比较密集,可以集中在8位范围内还是偶数如果真要写入32位有效数如何做?先写一条指令 mov r0, 0x5678 再写 movt r0, 0x1234 写到高16位,ida会两句合成一句伪指令78 06 05 E3 34 02 41 E3 MOV R0, #0x12345678
寄存器
Move(register)将值从寄存器复制到目标寄存器。
上面说的是立即数到寄存器,这个是寄存器到寄存器
除了: 01 00 A0 E1 MOV R0, R1还能: 01 02 A0 E1 MOV R0, R1,LSL#4 (R0是一个操作数,R1,LSL#4整体是一个操作数)R1向左移动4位写到r0里看第7-11位,5位的长度也就是2的32次方来表示偏移第5-6位,stype2位的长度有4种情况,逻辑左移,逻辑右移,算术右移 ,循环移位(算术左移的逻辑和逻辑左移是一样的,循环移位不区分左右移,比如循环左移1位和循环右移32位是一样的)此指令由别名 ASRS (immediate), ASR (immediate), LSLS (immediate), LSL (immediate), LSRS (immediate), LSR (immediate), RORS (immediate), ROR (immediate), RRXS, and RRX使用. 指令lsl r0, r1,4 的效果跟 R0, R1,LSL#4 是一样的所以 ASRS, ASR, LSLS, LSL, LSRS, LSR, RORS, ROR, RRXS, RRX 实际上都可以认为是mov指令的一个宏,另一种写法,在ida中都会翻译成mov指令常用的也就是逻辑左移,逻辑右移,算术右移,都是一些数组,结构体偏移寻址的
寄存器移位寄存器
Move(寄存器移位寄存器)将寄存器移位后的寄存器值复制到目标寄存器。
例如:11 02 A0 E1 MOV R0, R1,LSL R2
基本整型运算
指令基本都是3个操作数,第一个是写入,第二三个是做运算。(寄存器,寄存器,立即数) 或者是 (寄存器,寄存器,寄存器)。
下面指令都有多种格式,立即数,寄存器,移位寄存器等等。只列举立即数的情况
ADD, ADDS (immediate)
加法指令。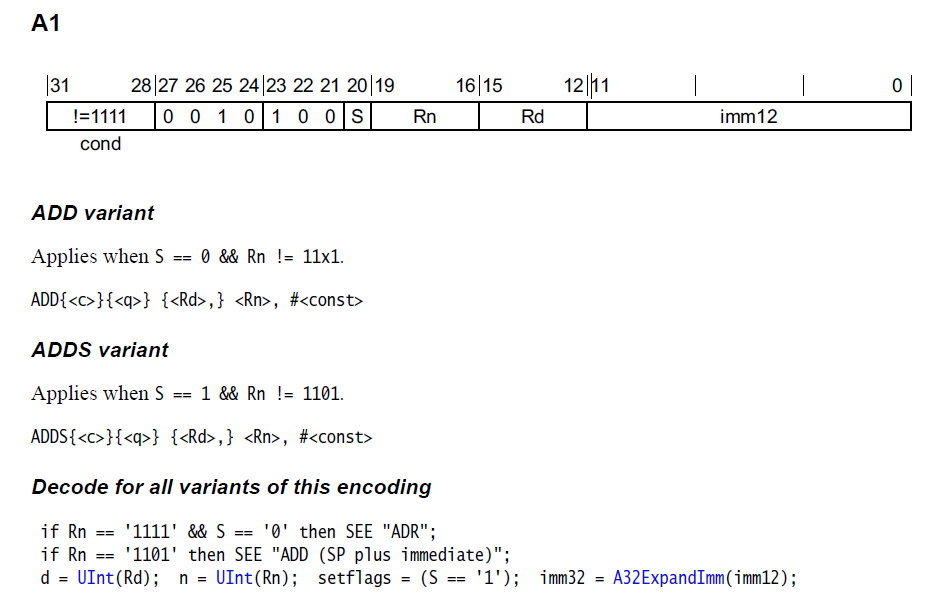
立即数长度12,分为有效数字低8位,高4位做位移循环。这种叫A32ExpandImm,把imm12扩展成32位
ADD, ADDS (register)

ADR
将地址加载到寄存器的伪指令。从PC相对地址将立即值添加到PC值以形成PC相对地址,并写入结果发送到目标寄存器。该指令由伪指令ADD(立即,到PC)和SUB(立即,从PC)使用。这个伪指令从来都不是首选的反汇编。例如指令 add, r0, pc, 4(把pc+4赋给r0)会在ida变成04 00 8F E2 ADR R0, loc_16FD4从pc+4会涉及到读pc,读pc 要+8,加上4就是1200016FD0 04 00 8F E2 ADR R0, loc_16FDC00016FDC loc_16FDC
SUB
减法指令。从PC中减去从对齐(PC,4)值减去立即值以形成一个PC相关地址,并将结果写入目标寄存器。02 00 41 E0 SUB R0, R1, R2(r0=r1-r2)
RSB
反向减法指令。反向减法指令,反向减法(立即数)从立即数中减去寄存器值,并将结果写入目的地寄存器。08 00 61 E2 RSB R0, R1, #8(8-r1的值写入r0)08 00 61 E2 RSB R0, R1, R2(r2-r1的值写入r0)
AND
按位与运算指令。按位与(立即数)对寄存器值和立即数执行位与,并将结果写入到目标寄存器。02 00 01 E0 AND R0, R1, R2(r0 = r1 & r2)
BIC
按位与非运算指令。逐位清除(立即数)对寄存器值和立即数的补码执行逐位“与”运算,并将结果写入目标寄存器。相当于第二个操作数和第三个操作数取反之后取and02 00 C1 E1 BIC R0, R1, R2(r0 = r1 & ~r2)
ORR
按位或运算指令。逐位OR(立即数)执行寄存器值和立即数的逐位(包括)OR,并将结果写入目标寄存器。02 00 81 E1 ORR R0, R1, R2 (r0 = r1 | r2)
EOR
按位异或运算指令。逐位异或(立即数)对寄存器值和立即数执行逐位异运算,并将结果写入目标寄存器。02 00 21 E0 EOR R0, R1, R2(r0 = r1 ^ r2)
LSL
逻辑左移指令。逻辑左移(立即数)将寄存器值左移立即数位,移位为零,并将结果写入目标寄存器。
lsl r0, r1, r2 11 02 A0 E1 MOV R0, R1,LSL R2(r0 = r1 << r2)
LSR
逻辑右移指令。逻辑右移(立即数)将寄存器值右移一个立即数位数,移位为零,并将结果写入目标寄存器。
lsr r0, r1, r231 02 A0 E1 MOV R0, R1,LSR R2(r0 = r1 >> r2)
ASR
算术右移指令。算术右移(立即数)将寄存器值右移立即位数,将其符号位的副本移位,并将结果写入目标寄存器。
asr r0, r1, r251 02 A0 E1 MOV R0, R1,ASR R2(r0 = r1 >> r2)
asr r0, r1, r2和lsr r0, r1, r2是一致的吗
在一般情况下,asr r0, r1, r2 和 lsr r0, r1, r2 是不一致的。asr r0, r1, r2 执行算术右移,将 r1 的所有位向右算术移动 r2 位,并将结果存储到 r0 中。算术右移在移位过程中用符号位填充左侧空出的位,即最高位(符号位)保持不变。lsr r0, r1, r2 执行逻辑右移,将 r1 的所有位向右移动 r2 位,并将结果存储到 r0 中。逻辑右移在移位过程中用0填充左侧空出的位。因此,在 asr 中,符号位会影响右移时左侧空出位的填充值,而在 lsr 中,左侧空出位总是用0填充。如果 r1 是一个带符号整数,asr 和 lsr 通常会得到不同的结果。
- 举例:
- 当考虑一个假设的8位寄存器的情况,其中最高位(MSB)表示符号(0表示正数,1表示负数)时,我们可以通过一个例子来说明 asr 和 lsr 的区别。
假设 r1 是二进制表示为 11011010,这是一个用二进制补码表示的负数。现在,让我们使用 asr 和 lsr 进行右移操作。
1 | ; 假设 r1 是 11011010(二进制表示),是一个负数 |
在这个例子中,asr 在右移过程中保留了符号位,导致结果仍然是负数。而 lsr 在填充左侧空出位时使用了 0,导致结果变为正数。这展示了算术右移和逻辑右移在处理符号位上的差异。
访存指令
访存:LDR:从内存中加载数据到寄存器。STR:将寄存器中的数据存储到内存。
1.数据流向2.操作的寄存器和内存地址3.后续附加行为 块访存指令的语法是 {寄存器列表},其中寄存器列表中的寄存器按照从右到左的顺序依次被处理。这意味着在执行块访存指令时,先处理列表中的最右边的寄存器,然后依次向左处理。
LDR
加载寄存器(立即)从基本寄存器值和立即偏移中计算一个地址,从内存中加载单词,然后将其写入寄存器。 它可以使用偏移,索引或预先指定的地址。04 00 91 E5 LDR R0, [R1,#4]r1是一个基址寄存器,4是偏移量,表示从基址开始往后移动4个字节的位置。也可以使用负偏移04 00 11 E5 LDR R0, [R1,#-4]02 00 91 E7 LDR R0, [R1,R2]02 02 91 E7 LDR R0, [R1,R2,LSL#4]上面指令都是没有后续附加行为的04 00 B1 E5 LDR R0, [R1,#4]! (加了!后除了把值写进r0,还会更新r1的地址,地址+4)
上述的指令都可以算是内偏移,还有外偏移的04 00 91 E4 LDR R0, [R1],#4(从r1读出来的内存给r0后,后续行为把r1+4)
STR
存储寄存器(立即寄存器)根据基址寄存器值和立即偏移量计算地址,并将寄存器中的值存储到内存。它可以使用偏移量、后索引或前索引寻址。0404 00 81 E4 STR R0, [R1],#4(将寄存器 R0 中的值存储到内存地址 R1 指向的位置,然后将 R1 的值递增 4(即地址加上 4))
可以使用LDR,STR来操作sp栈指针寄存器,达到pop和push的效果当需要从sp取值到寄存器的时候,也就是pop,要用ldr,因为pop取值释放了空间,所以取值后sp栈指针要加4而向sp放入值的时候,也就是push,要用str,因为push要分配空间,所以放值后sp栈指针要减4。对于典型的栈操作,递减栈指针意味着在栈上分配一段新的空间,而递增栈指针则表示释放栈上的空间。在常见的体系结构中,栈是向低地址方向增长的,因此递减栈指针实际上是在向栈的底部分配空间。
pop:
- LDR R0, [SP], #4 等同于下面两条 ldr r1, [sp] // 从栈中加载值到寄存器 r1 add sp, sp, #4 // 栈指针递增4个字节
push:
- STR R0, [SP, #-4]! 等同于下面两条sub sp, sp, #4 // 栈指针递减4个字节 str r0, [sp] // 将寄存器 r0 中的值存储到栈中
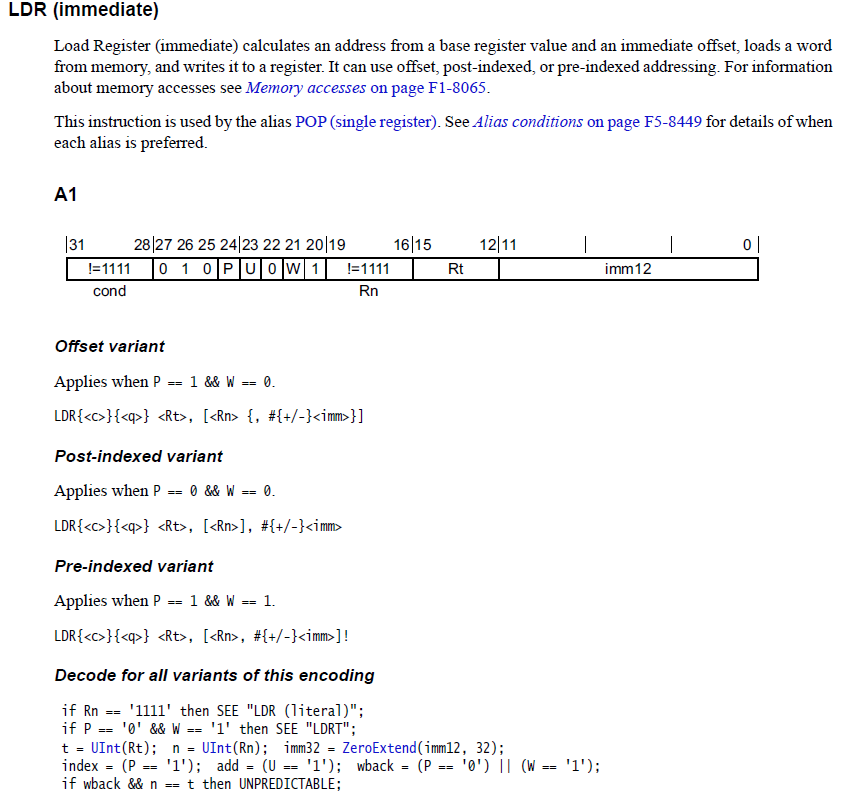
ldr的12位立即数是0扩展的,只支持12位,第23位U是表示正负的,第24位P是表示内外偏移的。str也是同理
块访存指令
块访存也是访存,读内存就是LDM开头,写内存STM开头,M表示多个数据或多个寄存器当我们在使用LDM或STM指令时,是想加载或存储寄存器值之前还是之后增加或减少基址寄存器的值,这影响了加载或存储完成后基址寄存器的最终值。LDM和STM指令可以跟随以下后缀:IA,IB,DA,DB。第一个操作数后续还能加 ! :表示在加载或存储完成后更新寄存器。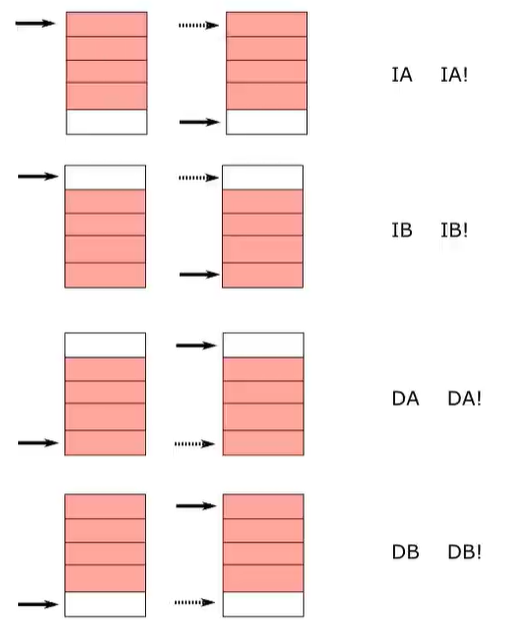
简单归纳就是IA:访问这块指针后,再向后加4。IB:还没访问这块指针,先向后加4,再访问。DA:反向读4字节,然后减4DB:先减4,然后再访问 !表示最后指针的地址是否更新常用只有LDMIA!,STMDB!,当第一个操作数为sp,等价于pop和push再ida中指令为 stmdb sp!,{r0-r3} 会自动替换为0F 00 2D E9 PUSH {R0-R3}或0F 00 2D E9 STMFD SP!, {R0-R3} 这两个是一样,在不同ida版本会显示不同当第一个操作数是sp!时,ida会翻译成STMFD。第二个操作数无论是写 {R2,R1,R4,R3} 也会翻译成 {R1-R4},寄存器标号小的放在低地址,寄存器标号大的放在高地址。FD是用来操作栈的,当第一个操作数是sp时候,LDMFD等价于LDMIA,STMFD等价于STMDB。ida也会优先翻译为LDMFD,STMFD。当sp加了!后,则会优先翻译为POP和PUSH。
- 例子:
- LDMIA SP, {R1-R4} ==> LDMFD SP, {R1-R4} STMDB SP, {R1-R4} ===> STMFD SP, {R1-R4} LDMIA SP!, {R1-R4} ==> POP {R1-R4} STMDB SP!, {R1-R4} ==> PUSH {R1-R4}
对于初学者先简单理解掌握下面三种STMFD == PUSHLDMFD == POP***IA: 快速复制内存,根据前缀看是读还是写
分支和模式切换
分支:B,BL,BX,BLX
- 跳转目标2. 模式切换,thumb和arm的切换3. 写入LR的值
后续是加立即数还是寄存器,分为以下几种情况:B immBL immBX regBLX immBLX reg
B
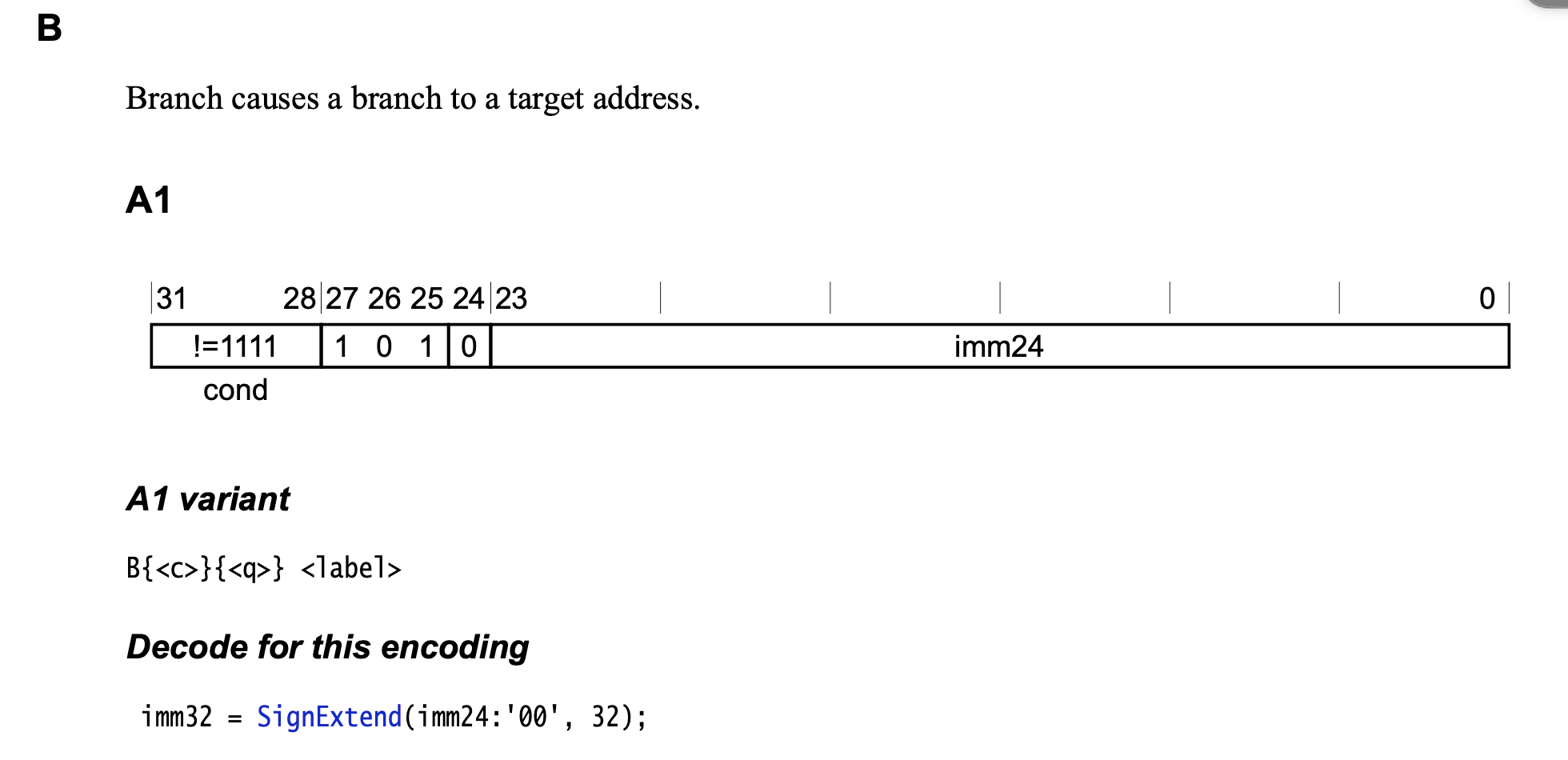
B指令是无条件跳转,不带模式切换,T标志位不变。如果是从arm跳转thumb,或者thumb跳转到arm,需要保证跳转前后的模式统一。把指令机器码改为 00 00 00 EA,会发现要跳转的地址是当前地址+8,01 00 00 EA 则要跳转的地址是8+立即数4(当前立即数为1)。如果是thumb模式下,则是8+立即数2。当00 00 00 EA会加8,那么FE FF FF EA 则是8+(-2*4),即一直跳转到自己当前地址,进入死循环。FE FF FF EA 需要记住,当一个进程很快执行结束的时候,又需要进行调试的时候。用ida找到文件_start的地方,elf文件加载到内存中,_start是程序的入口点。可以同010 Editor对这个入口位置的指令修改为 FE FF FF EA。push到设备重新运行就断住了,再把指令改回来,就可以调试。B指令的立即数可以寻址的范围是从当前指令的地址向前或向后移动的距离。由于立即数是相对偏移量,因此它可以覆盖的地址范围是从PC - 32MB到PC + 32MB。thumb模式下立即数只会更短
例如:
- 假设当前指令的地址是0x80000000(32位地址),并且B指令的立即数字段(imm24)的值为0x001234。将imm24与两个零(’00’)连接起来,得到一个32位的立即数:imm32 = 0x00123400。
- 如果imm24是一个正数(无符号值),那么imm32的最高有效位将为零,扩展后的结果仍然是正数。例如,如果imm24的值为0x001234,那么imm32 = 0x00123400。
- 如果imm24是一个负数(有符号值),那么imm32的最高有效位将为1,扩展后的结果仍然是负数。例如,如果imm24的值为0xFF1234,那么imm32 = 0xFF123400。
- 将PC的当前值(0x80000000)与imm32进行相加,即PC + imm32,就可以得到B指令跳转的目标地址。目标地址为0x80000000 + 0x00123400 = 0x80123400,根据前面提到的寻址范围,PC - 32MB到PC + 32MB是从0x7F800000到0x80000000+0x02000000的范围。在这个例子中,PC的当前值为0x80000000,而且目标地址0x80123400是在这个范围之内,因此B指令是可以正确寻址和跳转的。
BL
BL指令后面加立即数,也是无条件跳转,但是会写入LR的值。执行完会把bl指令的下一条指令的地址写入到LR。如果是在thumb下,会把bl下一条指令的地址异或T位,也就是1,地址会变成奇数写入LR。当程序需要返回的时候通过LR的最低位来返回arm模式还是thumb模式,0就是arm,1就是thumb。
BX
BX指令后面加寄存器,BX会把寄存器的值拆成两部分,最低位会写入T标志位,用于指示跳转的目标指令集,剩余的部分写入pc寄存器,作为跳转的目标地址。通俗点就是如果地址是奇数,最低位就是1,偶数则是0。T标志位用于指示跳转目标的指令集,0表示ARM指令集,1表示Thumb指令集。
BLX
有两种情况,立即数和寄存器。BLX+立即数是一定会带有模式切换的,并会把执行完会把blx指令的下一条指令的地址写入到LR,把当前T标志位写入LR值的最低位后再更新T标志的值。BLX+寄存器跟BX+寄存器一样,会把执行完会把blx指令的下一条指令的地址写入到LR,是否模式切换以及T标志的值看寄存器地址的最低位。
使用mov跳转
跟BX reg做对比, mov pc, r0 指令将会直接将寄存器 R0 的值复制到程序计数器 PC,这意味着它是一个非条件的直接分支,不会进行任何模式切换,而且不会修改 T 标志位。
使用ldr跳转
直接从内存加载地址到pc, ldr pc, [r0],把r0寄存器指向的值给pc,这种也会根据寄存器的值奇偶数来切换模式,并更新T标志位。有三种跳转指令 B系列指令,mov,ldr。其中mov最弱,不带有模式切换,一般也很少用。ldr指令调用一个导入表的方法
判断导出表函数的模式
怎么判断导出表的函数时arm模式还是thumb模式?再ida中查看libc的导出表函数时,address都是偶数,难道全都是arm模式吗?比如printf函数,地址是偶数,点击进去又是thumb指令。那在其它文件调用这个导出表函数时,如何正确知道函数是哪种模式?readelf -s libc.so > a.txt可以显示库的所有导出符号表,
1 | ... |
下面是在ida中的地址
在ida中的地址是1e774,通过readelf的地址是1e775,所以就能判断出printf是thumb模式的,在调用printf的时候,会把拆成两部分,最低位写入T标志位,跳转的时候自动模式切换了。这也就解释了在使用frida在hook thumb函数地址的时候为什么要加1了。
Thumb模式
在thumb下短指令也就是2字节的指令一般不使用r8-r12寄存器,如果使用了就会编译为长指令。一般也没有条件码和标志响应位,运算指令优先对第一,第二操作数相同情况下用短指令编码,以提高代码密度。这种优化可以减少指令数量和代码大小。比如:add r0, r0, r1 会自动转为 add r0, r1还有一些情况当短指令编码编译不过的时候编译器会在指令后缀+.w进行4字节指令编码。add.w r0, r0, r1
IT指令块
IT 指令是 Thumb 指令集中的一种条件执行指令,用于在紧接着的多条指令中根据条件选择性地执行。IT 指令块由一个条件码和最多四条紧接着的指令组成,它们构成了一个条件执行块。在条件执行块中,只有在满足条件时才会执行相应的指令。IT 指令的格式如下:IT{<x>{<y>{<z>}}}{<q>} <cond>
IT 指令块由可选的后缀(x, y, z)和一个可选的条件码(q)组成。 后缀 x, y, z 分别指示条件执行块中的第一条、第二条和第三条指令。 <q> 是可选的条件码,用于指定条件执行块的执行条件。 如果条件码 <q> 不存在,则默认情况下,IT 指令块中的所有指令都受到相同的条件码
调用约定和栈帧分析
调用约定
前4个参数:r0-r3,其他参数栈传递非易变寄存器:r4-r11
r11: 栈帧指针r12: 导入表寻址测试代码,使用ndk build后用ida打开
1 |
|
前4个参数
前4个参数通常会被依次传递到寄存器 R0 到 R3 中。这样设计的原因是为了尽可能地利用寄存器,以提高函数调用的效率。如果函数需要的参数超过4个,那么额外的参数就会被放置在栈上。
1 | .text:00000628 ; int __cdecl main(int argc, const char **argv, const char **envp) |
非易变寄存器
在 ARM 架构中,寄存器 R4 到 R11 被称为非易失性寄存器,通常用于存储在函数调用期间需要被保留的临时数据,因此,如果一个函数在调用期间修改了这些寄存器的值,它必须在返回之前恢复这些寄存器的原始值,以确保调用者的寄存器值不会被破坏。
栈帧指针
在 ARM 架构中,寄存器 R11 通常被用作栈帧指针,栈帧指针是一个指向当前函数栈帧的指针,栈帧是在函数调用期间分配的一块内存区域,用于存储局部变量、函数参数、返回地址等信息。 通常情况下,当一个函数被调用时,它会在栈上创建一个新的栈帧,并将栈帧指针指向这个新的栈帧。在函数内部,通过栈帧指针可以方便地访问栈帧中的局部变量和参数。而当函数返回时,栈帧指针会被恢复到上一个函数的栈帧,以便正确地返回到调用函数。
1 | .text:000005C0 ; int fun(int a, int b, int c, int d, int e, int f) |
函数开头PUSH {R11,LR}MOV R11, SP这两条指令是函数开头的典型指令序列,通常用于建立函数的栈帧。这里的操作可以理解为:PUSH {R11, LR}:将当前函数的栈帧指针 R11 和返回地址 LR 压入栈中。这是为了保存这两个寄存器的值,以便函数执行完毕后能够正确地恢复到函数调用前的状态。 MOV R11, SP:将当前栈指针 SP 的值复制到 R11 中。这样做是为了在函数中能够方便地访问栈帧中的局部变量和其他信息。通常情况下,函数的局部变量和参数会相对于栈帧指针来进行访问。 通过这两条指令的组合,函数建立了自己的栈帧,并将栈帧指针存储在 R11 中,以便在函数内部能够轻松地访问栈上的数据。函数结尾MOV SP, R11 将栈帧指针 R11 的值赋给栈指针 SP,恢复栈指针到函数调用前的状态。POP {R11,PC} 从栈中依次弹出 R11 和 PC 寄存器的值。
导入表寻址
R12 寄存器用于进行导入表寻址。导入表是一个数据结构,存储了函数的地址或函数指针。在动态链接库(DLL)或共享库中,当程序调用一个外部函数时,需要在运行时动态解析函数的地址,这就需要导入表。
1 | .plt:00000520 ; int printf(const char *format, ...) |
注意:函数的返回值是放在R0里的下面是根据上面反汇编模拟执行的栈指针,根据执行main和fun函数的栈地址偏移表示如下:
1 | $-30 | ret_printf <-- sp fun |