
介绍
Base64是一种基于64个可打印字符来表示二进制数据的表示方法,是一种编码方式,提及编码方式,必然有其对应的字符集合。在Base64编码中,相互映射的两个集合是:
二进制数据{0, 1}
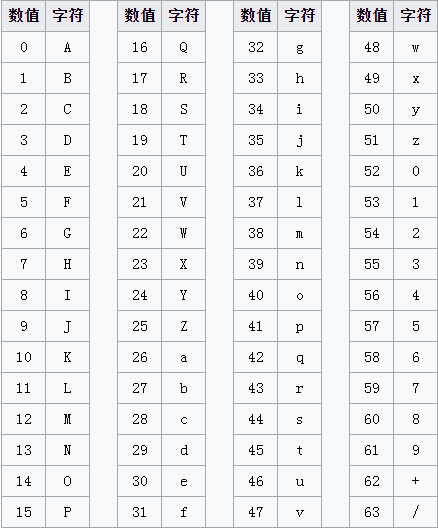
{A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, +, /}
Base64编码方式可使得信息在这两种字符集表示法之间相互等价转换。
Base64编码过程
由于base64的字符集大小为64,那么,需要6个比特的二进制数作为一个基本单元表示一个base64字符集中的字符。因为6个比特有2^6=64种排列组合。
具体来说,编码过程如下:
- 将每三个字节作为一组,共24bit,若不足24bit在其后补充0;
- 将这24个bit分为4组,每一组6个bit;
- 在每组前加00扩展为8个bit,形成4个字节,每个字节表示base64字符集索引;
- 扩展后的8bit表示的整数作为索引,对应base64字符集的一个字符,这就是base64编码值;在处理最后的不足3字节时,缺一个字节索引字节取3个,最后填充一个=,;缺两个字节取2个索引字节,最后填充==。
解码时将过程逆向即可。
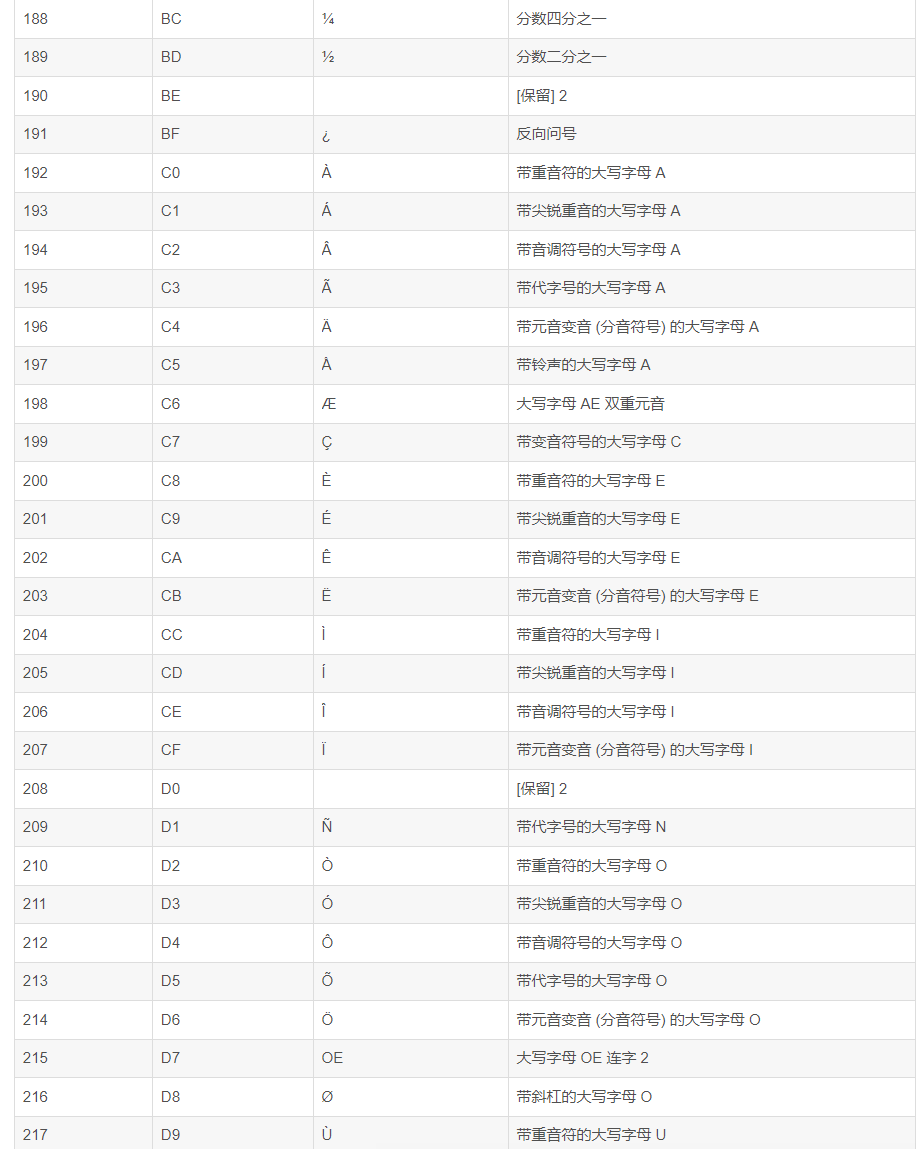
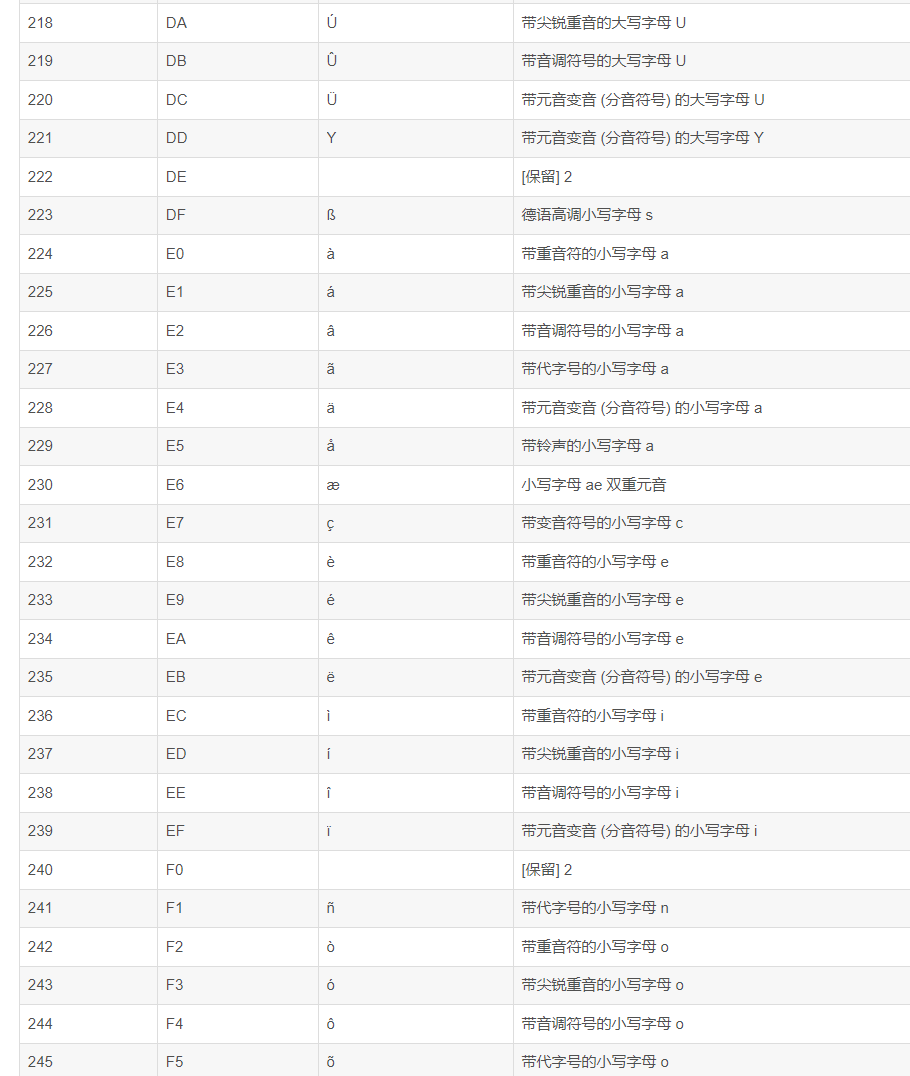
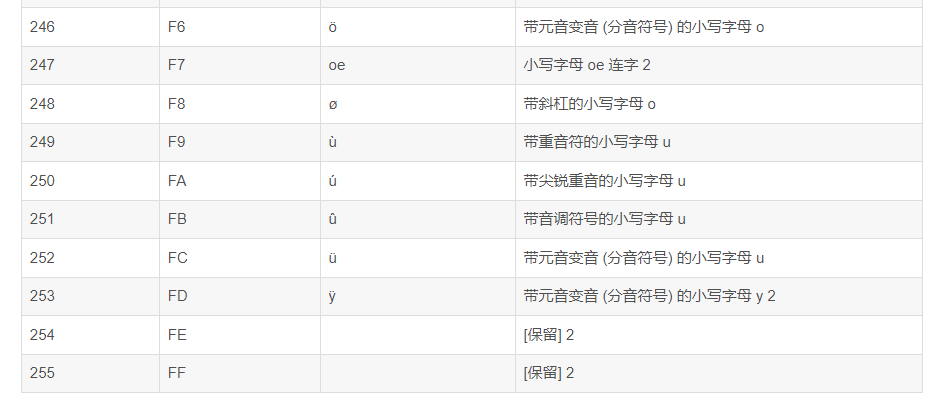
Base64索引表:
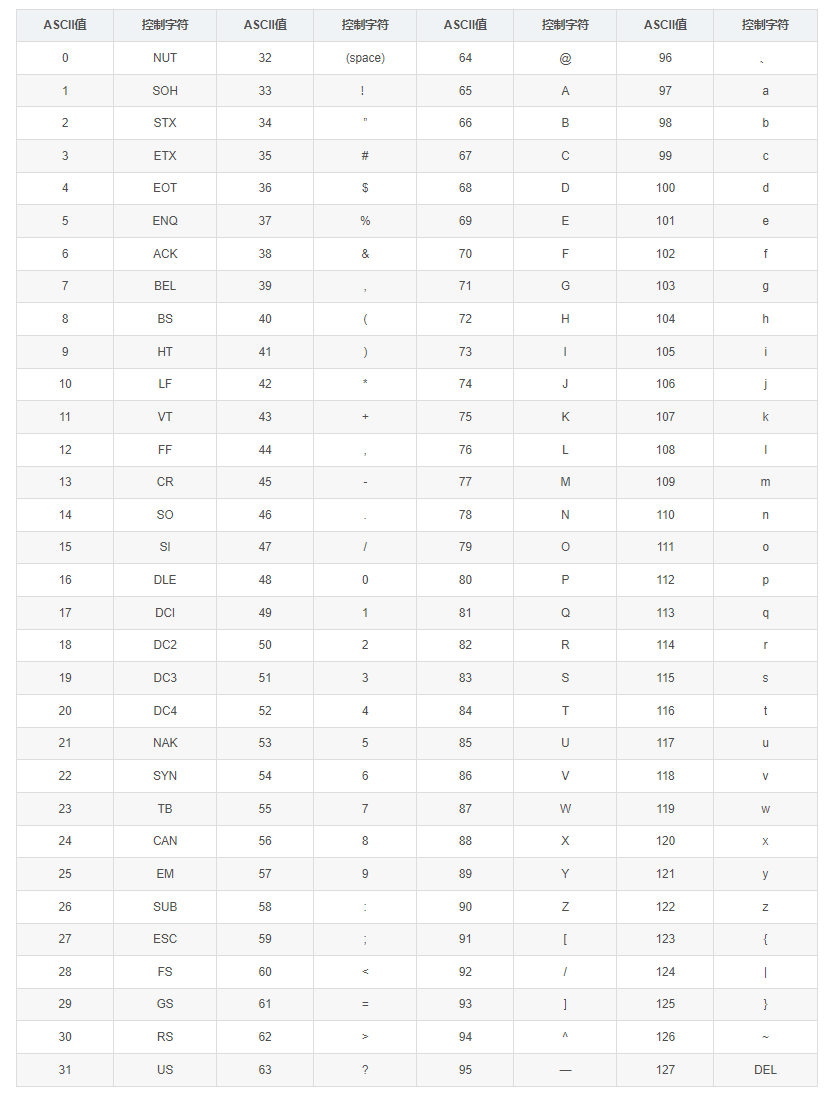
ASCII码表
编码示例
示例一
Man的base64编码
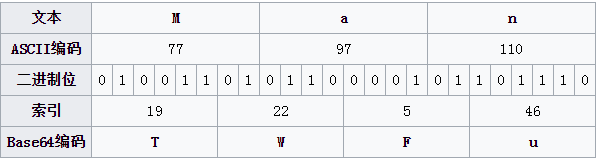
- 第一步,’M’, ‘a’, ‘n’的ASCII值分别为77, 97, 110,对应的二进制值分别为:01001101, 01100001, 01101110;取三个字节共24bit:010011010110000101101110
- 第二步,将这24bit分为4组,每组6个bit:010011, 010110, 000101, 101110
- 每组前面加00,形成4个字节的,00010011, 00010110, 00000101, 00101110, 即19, 22, 5, 46
- 根据索引表,对应的base64字符分别是T, W, F, u
最后的base64字符串是: TWFu。
解码时将过程逆向即可。
示例二
剩余两个字节,BC的base64编码

- 第一步,’B’, ‘C’的ASCII值分别为66, 64, 对应二进制值分别为:01000010, 01000011;取三个字节,不足不0,共24bit:01000010, 01000011, 00000000
- 第二步,将这24bit分为4组,每组6个bit:010000, 100100, 001100, 000000
- 每组前面加00,形成4个字节的,00010000, 00100100, 00001100, 00000000,即16, 36, 12, 0
- 由于’B’, ‘C’只有两个字节,缺一个字节,因此取3个索引;根据索引表,对应的base64字符分别是Q, k, M,最后填充一个=
最后的base64字符串是:QkM=
示例三
剩余一个字节,A的base64编码

- 第一步,’A’的ASCII值65, 对应二进制值为:01000001; 取三个字节,不足不0,共24bit:01000001, 00000000, 00000000
- 第二步,将这24bit分为4组,每组6个bit:010000, 010000, 000000, 000000
- 每组前面加00,形成4个字节的,00010000, 00010000, 00000000, 00000000,即16, 16, 0, 0
- 由于’A’只有一个字节,缺两个字节,因此取2个索引;根据索引表,对应的base64字符分别是Q, Q,最后填充==
最后的base64字符串是:QQ==
Python实现
base64编码方式一:
1 | """ |
base64编码方式二:
1 | base64_charset = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' |
base64解码方式三:
1 | def decode(base64_str): |
c++实现
1 | // |
中文的base64编码
其实base64编码只是在二进制与base64字符集之间映射的编码,与其他字符集毫无关系。其他字符集想要转换为base64编码,只需先将其转换为二进制,再做base64编码即可。
那么对于Unicode字符集而言,有多种编码方式将其装换为二进制,所以在编码过程中就需要统一编码,以免造成乱码。上述Python示例就将中文转换为base64,首先使用默认编码utf-8将字符串转换为二进制(使用Python的str.encode()),再做base64编码;解码时候同样如此,先将base64字符串解码为二进制,再将二进制转换为字符串(使用Python的str.decode())